Learning Paths
Last Updated: April 22, 2026 at 12:30
Transactional Outbox Pattern: Solving the Dual-Write Problem for Reliable Message Delivery
A practical guide to reliable message delivery, dual-write safety, and saga recovery in distributed systems
The Transactional Outbox Pattern solves the dual-write problem in distributed systems by ensuring business data and outgoing messages are stored atomically in the same database transaction. This prevents message loss caused by crashes between database commits and broker publishing. A background relay safely delivers these stored messages, enabling reliable, at-least-once message delivery across services. It is a foundational pattern for building consistent event-driven architectures and resilient microservices.
Introduction
Modern applications rarely act in isolation. When a customer places an order, your Order service does not just save a record—it needs to tell the Inventory service to reserve stock, perhaps trigger a notification, perhaps kick off a payment flow. In a monolith with a single database, all of this happens inside one transaction. If anything fails, it all rolls back. Clean.
In a distributed system, that guarantee disappears. Notifying another service means publishing a message to a broker or calling an API—neither of which can participate in your database transaction. So you save the business record, then you send the message. Two separate operations with no atomic guarantee between them.
Now imagine your server crashes between those two steps. The order is saved. The message was never sent. The Inventory service never found out. You have a confirmed order with no stock reserved.
This is the dual-write problem, and it is one of the most common sources of silent data corruption in distributed systems.
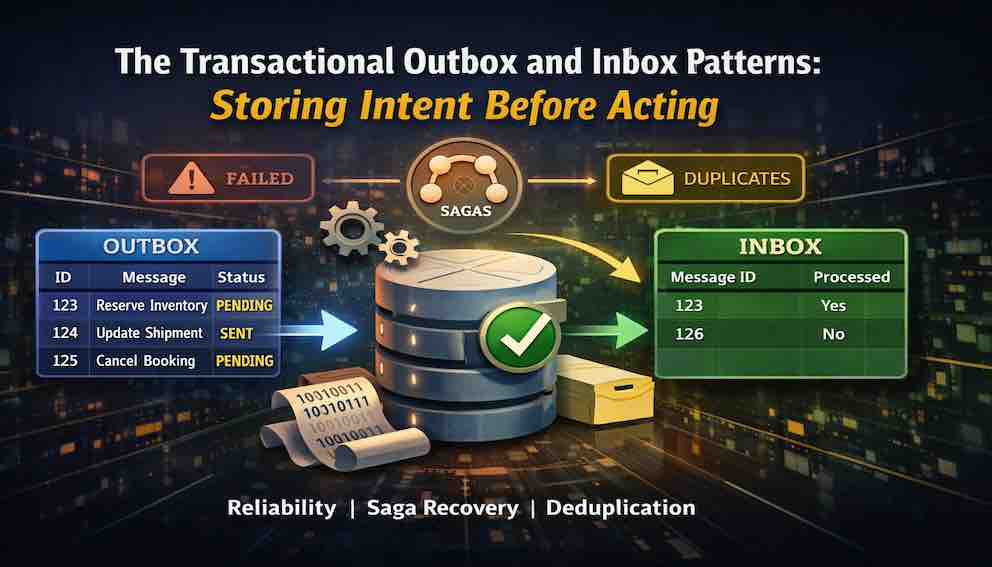
The Transactional Outbox pattern solves it. The core idea is simple: instead of sending messages directly from your business transaction, write them to a database table—the outbox—in the same transaction as your business data. A separate background process then reads from that table and forwards the messages on. Because the intent is stored atomically with the business change, a crash cannot separate the two.
The outbox can be thought of as a write-ahead log for business actions. It records not just what has happened in the system, but also the messages the system intended to send next. This makes the database the single source of truth for both state changes and downstream communication.
What Problem Does It Solve?
The Dual-Write Problem
The failure is straightforward to trace. Your service executes two operations in sequence: write to the database, then publish a message. If the process crashes between them, the database write survives but the message does not. When the service restarts, there is nothing to retry—the message was never recorded anywhere. It is simply gone.
The inverse failure is equally dangerous. If you publish the message first and then write to the database, a crash between the two leaves the message published but the database unchanged. The downstream service acts on a change that your service has not yet recorded. You have created a fact in the world that your own system does not believe.
Neither ordering is safe. The problem is not timing or retry logic—it is that the two operations are fundamentally not atomic.
Why Retries Do Not Fix This
Retrying a published message only helps if the message itself was durably recorded somewhere in the first place. Without an outbox, a crash between writing the business data and publishing the message means the message never existed beyond memory. There is nothing reliable to retry.
How It Works
The flow has two parts: the write and the relay.
The write happens inside your normal business transaction. When you save the order, you also insert a row into the outbox table describing the message you want to send—the message type, the payload, which aggregate it relates to. Both rows commit together or neither does. The outbox row is your durable record of intent.
The relay is a background process that runs independently. It polls the outbox for pending rows, sends each message to its target—a broker, an API, another service—and marks each row as sent (meaning the message has been published, not necessarily consumed or processed). If the relay crashes mid-batch, it picks up where it left off on the next run. The outbox row survived the crash, so the message survives too.
Because the relay can crash after sending but before marking a row as sent, duplicate messages are possible. Consumers must be designed to handle this—typically using an inbox pattern or idempotency keys on the receiving side.
Every failure scenario resolves through retry. The outbox is the durable foundation that makes retry safe.
The Outbox Table
At its simplest, the outbox table stores messages that still need to be delivered. Each row represents one message the system intends to send.
You start with four core fields.
An ID uniquely identifies the message so it can be safely retried and tracked over time. A message type tells the relay what kind of action this represents—such as OrderCreated or PaymentFailed. A payload contains the actual data that downstream systems need to act on. A status field tracks where the message is in its lifecycle, such as pending, sent, or failed.
These four fields are enough to make the basic relay work.
In real systems, however, you quickly need more control over when and how messages are retried.
An aggregate_id links the message to a business entity, such as an order or customer. This is important because it allows you to reason about ordering—for example, ensuring all events for a single order are processed in sequence, even if different orders are handled in parallel.
A retry_count tracks how many times delivery has been attempted. This is used to decide when to stop retrying or increase backoff delays.
A next_attempt_at timestamp controls when the relay should try again, rather than retrying immediately. This is what enables exponential backoff and prevents repeated hammering of failing systems.
A last_error field captures the reason for the most recent failure, which becomes essential for debugging stuck or poisonous messages.
Finally, you often need locking or lease fields so multiple relay workers can run safely in parallel. These fields ensure that once a worker picks up a message, others do not process the same row at the same time.
The aggregate_id deserves special attention. It is what lets you preserve ordering per business entity while still scaling processing horizontally. Without it, messages from the same order can be processed out of sequence, even if the system is otherwise correct.
Together, these fields turn the outbox from a simple message store into a controlled delivery mechanism with ordering, retry behavior, and safe concurrency built in.
Running the Relay Safely
If multiple relay workers process messages at the same time, things can go wrong quickly. The same message may be picked up twice, leading to duplicate delivery.
To avoid this, each message must be safely “claimed” by a single worker before it is processed. This ensures that even in a distributed setup, only one worker handles a given message at any moment.
Failures also need to be handled carefully. If a message cannot be delivered, it should not be retried immediately. Instead, retries should be spaced out so that repeated failures do not overload the system or the downstream service. Over time, the delay between retries increases to give the system space to recover.
Together, safe claiming and controlled retrying ensure that the relay can run continuously without duplicating work or overwhelming dependencies.
The Outbox and Saga Recovery
One of the most valuable—and most overlooked—uses of the outbox is compensating transactions: the undo steps in a saga.
Consider a travel booking that reserves a flight, reserves a hotel, and charges a credit card. If the card charge fails, you must cancel the hotel and flight in reverse order. Without an outbox, your orchestrator sends the cancel commands one by one. A crash between them leaves the hotel cancelled but the flight blocked permanently—the customer is not charged, but the airline seat is gone.
With an outbox, both compensation commands are inserted in the same transaction that records the payment failure. Either both are stored or neither is. If the crash happens before that commit, the orchestrator retries from scratch. If it happens after, the relay eventually delivers both. Compensation becomes atomic at the intent level, even if delivery happens at different moments.
You can take this further. Rather than storing only compensation commands, you can store every saga step as it happens—each forward action and each undo—as outbox rows inserted atomically with the state change they accompany. Because every step's intent is written before it is attempted, the saga survives a crash at any point. On restart, the orchestrator reads the outbox and knows exactly what has been attempted and what to do next. The outbox becomes the saga's memory.
Operational Realities
Visibility and Monitoring
The outbox fails silently if you let it. You need to track queue depth—the number of pending or failed messages waiting beyond their next retry time—and alert if it grows for more than a few minutes. Watch the age of the oldest pending message; one stuck for hours means something is broken downstream. Watch the retry count distribution; messages retried several times are a signal worth investigating.
After a maximum retry threshold, stop retrying and move the message to a dead-letter state for manual review. Unbounded retries on a poison message will tie up your relay indefinitely.
Data Growth
The outbox table grows without limit if you do not clean it up. Archive or delete sent records after a retention window—seven days is a common choice. On high-volume systems, partition the table by date so old partitions can be dropped wholesale rather than row by row.
The Outbox vs. the Inbox
The outbox solves the sending problem: ensuring a message is published reliably after a business write. The inbox solves the receiving problem: ensuring a message is not processed more than once after a crash.
They are symmetric patterns with the same core idea—store intent in the database, atomically with the operation it accompanies—and they are commonly deployed together. The outbox ensures your messages reach consumers. The inbox ensures those consumers act on each message exactly once. Together they give you reliable, end-to-end messaging without depending on the broker to provide guarantees it may not actually deliver.
When Not to Use This Pattern
If your broker already supports transactional message production—Kafka with exactly-once semantics, for example—you may achieve the same guarantee without an outbox, though transactional producers bring their own complexity and constraints. If losing the occasional message is genuinely acceptable—analytics events, non-critical notifications—the overhead of an outbox may not be worth it.
The pattern is also not limited to microservices. A monolith sending a welcome email after user registration, an IoT device syncing readings to the cloud, a backend triggering an S3 upload after a form submission—any situation where a reliable store meets an unreliable external action is a candidate. The pattern is older than microservices; versions of it have been used in banking systems since the 1990s.
But if losing a message means a saga hangs halfway through compensation, an inventory update is silently skipped, or a payment is recorded in one system and not another—use the outbox.
Testing the Pattern
Test against a real database and a real broker or stub. Mocks will not expose the timing and concurrency behaviour you need to verify.
Test 1 — Crash before relay sends. Write a business record and an outbox row, then stop the relay before it processes. Restart the relay. Verify the message is eventually delivered and the outbox row is marked sent.
Test 2 — Crash after send, before marking sent. Simulate the relay crashing after publishing a message but before updating the row to sent. On restart, verify the relay re-sends and that the consumer handles the duplicate gracefully.
Test 3 — Concurrent relay workers. Run two relay workers simultaneously against the same outbox. Verify each message is sent exactly once and that row-level locking or leases prevent double-processing.
Test 4 — Relay failure with backoff. Make the target service return errors. Verify the retry count increments, the next attempt time advances with exponential backoff, and the relay does not hammer the failing service.
Test 5 — Dead-letter threshold. Exhaust the retry limit on a message. Verify the relay moves it to dead-letter and stops retrying, and that an alert or log entry is produced.
Summary
The Transactional Outbox pattern solves a precise failure: losing a message because the server crashed between a database write and a broker publish.
By writing the message intent into the database in the same transaction as the business data, you eliminate that failure entirely. The relay delivers messages durably, with retries. Backoff and dead-lettering handle poison messages. Concurrency control prevents duplicate sends. Monitoring tells you when something is stuck.
For sagas, the same principle extends further: store compensation intent atomically at the moment you decide to compensate, and the saga survives any crash.
The outbox does not remove complexity from distributed systems. It makes one guarantee: if your system decided something should happen, that decision is never lost. Everything else—retries, duplicates, ordering—can be handled. Lost intent cannot.
About N Sharma
Lead Architect at StackAndSystemN Sharma is a technologist with over 28 years of experience in software engineering, system architecture, and technology consulting. He holds a Bachelor’s degree in Engineering, a DBF, and an MBA. His work focuses on research-driven technology education—explaining software architecture, system design, and development practices through structured tutorials designed to help engineers build reliable, scalable systems.
Disclaimer
This article is for educational purposes only. Assistance from AI-powered generative tools was taken to format and improve language flow. While we strive for accuracy, this content may contain errors or omissions and should be independently verified.