Learning Paths
Last Updated: May 26, 2026 at 16:30
Lean Software Development Principles: A Practical Introduction for Engineering Teams
Why individual teams perform well while the system underdelivers — and what Lean does about it
Most engineering teams trying to go faster focus on execution — more engineers, better tooling, higher velocity. Lean takes a different view: slow delivery is almost never an execution problem, it is a systems problem. This guide introduces the core lean software development principles — the seven principles, the seven types of waste, value streams, WIP limits, and the practical engineering habits that put Lean into action. It also includes a concrete five-step starting point so teams can begin applying Lean immediately, not just understand it in theory.
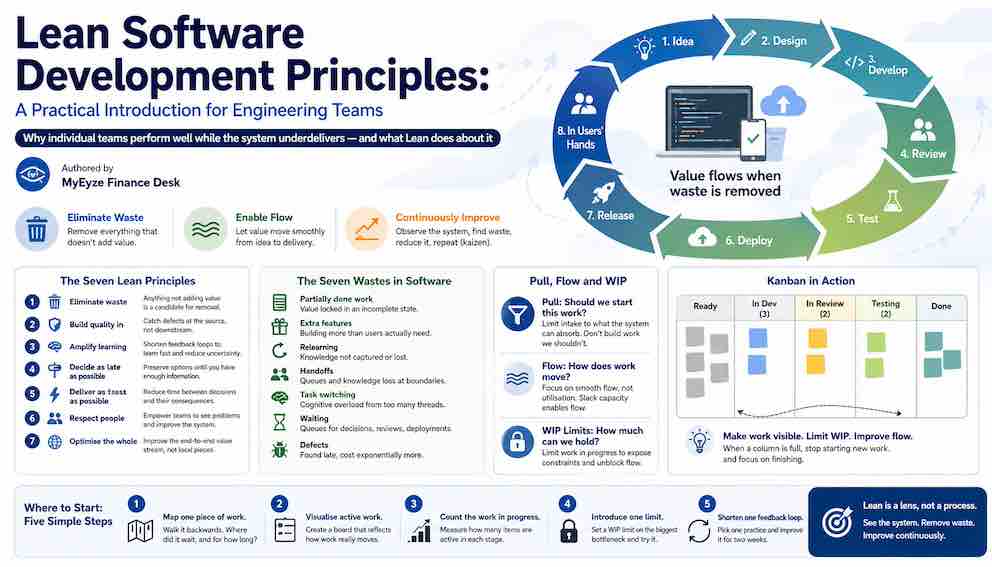
What actually slows software delivery down?
Most teams assume the answer is execution — and respond accordingly. More engineers, better tooling, higher velocity targets. That sometimes helps. But more often, delivery times barely change, because execution speed was never the real constraint.
Lean offers a different answer. It treats slow delivery as a systems problem, not a people problem. Originating with Toyota engineer Taiichi Ohno and adapted for software by Mary and Tom Poppendieck, Lean asks where value gets stuck — and removes those obstacles so that a feature moves smoothly from the moment it is conceived through design, development, testing, and deployment, all the way into users' hands.
The culprits are rarely the people. They are the system: rework that loops back through development, partially done work piling up in queues, decisions that nobody has the authority to make quickly.
The mental model is this: slow delivery is almost always a systems problem, not a people problem. Work gets stuck in waste — in queues, in rework, in unnecessary process, in decisions made too late. Find the waste, remove it, and value flows. Then find the next source of waste and repeat. That discipline, applied continuously, is what Lean is.
This article introduces the core ideas. Lean goes considerably deeper — into flow economics, portfolio-level pull systems, organisational design, and measurement theory — but none of that is accessible without the foundation covered here.
How Lean Thinks
Lean rests on three interlocking ideas.
The first is waste. Everything that consumes time and resources without delivering value to the user is waste. Lean's primary goal is to find it and eliminate it.
The second is flow. When waste is removed, work flows — moving steadily from idea to delivery without accumulating in queues, getting blocked on decisions, or cycling back through rework. Flow is the result of waste elimination, not a separate goal.
The third is continuous improvement. No system is ever fully optimised. Lean treats improvement as an ongoing discipline: observe the system, find the next source of waste, reduce it, repeat. Toyota called this kaizen.
Everything else in Lean — value streams, WIP limits, small batches — is a tool in service of one or more of these three ideas.
The Seven Lean Software Development Principles
The Poppendiecks formalised lean software development principles as seven ideas — the most important of which are covered here. Understanding them is the foundation for everything else Lean asks teams to do.
Eliminate waste is the foundational principle and the lens through which all others operate. If an activity does not add value from the user's perspective, it is waste — and waste is a candidate for removal. This means questioning not just what slows delivery down, but whether work should exist at all. Unnecessary features, redundant approvals, documentation nobody reads — all of it is waste until proven otherwise.
Build quality in means defects should be caught at the point of creation, not discovered downstream in testing or production. Quality is not a phase at the end of delivery — it is a property of every step. Automated testing, continuous integration, peer review, and clear requirements are all expressions of this principle. The later a defect is found, the more it costs: a misunderstood requirement caught in a conversation costs an hour; caught after six weeks of development it costs those weeks plus everything built on the wrong foundation.
Amplify learning recognises that software development is fundamentally a learning process. Teams start with incomplete knowledge about user needs, technical constraints, and what will actually work. Every build, every deployment, and every user interaction reduces that uncertainty — but only if the team is paying attention and shortening the feedback loops that bring new information in. The principle asks teams to design their work so learning happens fast: short iterations, fast feedback, frequent releases.
Decide as late as possible is often misread as procrastination. It is not. It means preserving options on decisions that are expensive to reverse until enough information exists to make them well. Architectural commitments, technology choices, structural design decisions — these are worth deferring when the cost of being wrong is high and information quality will improve with time. It does not apply to reversible decisions, where delay is simply indecision. The discipline is knowing which is which.
Deliver as fast as possible is about reducing the time between a decision and its consequences — not rushing. Fast delivery means smaller batches, shorter cycles, and earlier feedback. It means mistakes are caught before they compound, and changes in direction are cheap rather than catastrophic. Practically, it means breaking work into the smallest unit that delivers value, and removing everything that slows that unit from reaching users.
Respect people is the principle most often underweighted in technical discussions of Lean. Toyota's system worked because the people doing the work were trusted to see the problems and fix them. Frontline workers had genuine authority to stop the line, surface issues, and change the processes they worked within. In software, this means teams set their own WIP limits, own their processes, and have the authority to act on what they observe. The knowledge needed to improve the system lives closest to where the work happens. Respect for people is not just a value — it is how Lean organisations actually learn.
Optimise the whole is the systems-thinking principle. It is easy — and natural — to optimise the part of the system you control. But local improvements often create problems elsewhere: a team that ships code faster than it can be reviewed creates a review queue; a team that deploys frequently without investing in observability creates an operations problem. The only valid optimisation target is the full value stream, from idea to delivery in users' hands. Everything else is local optimisation, and local optimisation is waste.
The Seven Types of Waste in Software Development
Lean calls anything that consumes resources without delivering user value muda — waste. The Poppendiecks mapped Toyota's seven waste categories to software — the key ones for software teams are covered below, though waste shows up in many forms beyond this list.
Partially done work — code written but not reviewed, features built but not released — is value locked in an incomplete state. It delivers nothing until it crosses the finish line, and it accumulates risk the longer it sits.
Extra features built beyond what users actually need add complexity, increase the surface area for bugs, and consume future maintenance capacity. Validate before building.
Relearning occurs when knowledge already acquired has to be reconstructed — a decision not recorded, a context not captured, a developer who leaves mid-feature.
Handoffs between people or teams are potential queue entry points and guaranteed knowledge loss. Context degrades at every boundary.
Task switching across multiple active threads carries cognitive overhead that compounds. Context-switching is often less productive than finishing things sequentially.
Waiting dominates most delivery systems. Every queue — for review, for a decision, for a deployment slot — is waiting-waste. Its cost is not just time lost but feedback delayed.
Defects cost exponentially more when found late. The Lean response is to move detection as close to creation as possible: automated tests, fast review, clear requirements up front.
One caution: not everything that looks like waste actually is. Architectural runway, exploratory prototypes, slack capacity — these appear inefficient but create options and reduce future waste. The question is not "is this shipping value right now?" but "is this creating options or consuming capacity without return?" Applying waste labels carelessly produces a culture that mistakes short-termism for efficiency.
The Value Stream
A value stream is the full sequence of steps from idea to delivery — design, development, review, testing, deployment, release. The crucial insight is that value streams cross teams. A feature's journey passes through multiple functions, each with its own priorities and queues.
This is why team-level metrics often lie. A development team completing stories quickly may be feeding work into a testing queue that is three weeks deep. Velocity looks fine; value is not flowing.
Value stream thinking asks not where work happens, but where it accumulates. Walking a real piece of work backwards through its history — when did it start, where did it wait, and for how long — almost always produces a surprising picture. The bottleneck is rarely where people assume it is.
This also answers a question most organisations struggle with: why can individual teams be performing well while the system consistently underdelivers? Each team optimises for what it can see and control. But value does not flow through teams — it flows across them. The gaps between teams, the handoffs and approval gates and queues that build at functional boundaries, are invisible to everyone and owned by no one. No amount of individual team performance closes that gap. Only looking at the system as a whole can.
Pull Systems: The Question Before the Queue
Flow optimisation asks how to move work through the system more efficiently. Pull systems ask a prior question: should this work be in the system at all?
Toyota controlled intake. Work entered not because a schedule said it should but because a downstream stage signalled it was ready. In software, the equivalent is capacity-aware planning: limiting what enters the delivery system to what it can absorb. Most organisations do the opposite — loading backlogs continuously and wondering why cycle times are long.
The deepest waste in many software organisations is work that should never have been started — features built on unvalidated assumptions, projects without clear priority. A pull system treats capacity as a constraint that governs intake, not just throughput. The question shifts from "how do we finish this faster?" to "should we be doing this at all?"
Flow Over Utilisation
The default mental model in most organisations is utilisation thinking: productivity means keeping people busy, and idle time is waste. This model is intuitive and wrong.
Software delivery behaves like a queueing system, not a production line. The relationship between utilisation and wait time is exponential — a team at 95% capacity has dramatically longer queues than one at 80%, because there is almost no slack to absorb variation. A motorway at 95% capacity does not flow slightly worse than one at 70% — one lane closure causes a jam that backs up for miles.
Lean replaces utilisation thinking with flow thinking. The target is not how busy people are, but how smoothly work moves through the system. Slack capacity is not inefficiency — it is a prerequisite for flow.
Kanban and WIP Limits
Kanban is Lean's operational layer. It manages flow by doing two things: making work visible across stages, and limiting how much can be in progress at any one time.
WIP limits are the core mechanism. When a stage is full, work cannot enter it — creating pressure to clear the blockage rather than pile more into the queue. This feels counterintuitive; the instinct when review is slow is to raise the limit, not hold it. But WIP limits are not capacity settings. They are signals. Holding them forces the constraint to be resolved rather than hidden.
Lean in Practice
Lean principles become concrete in the day-to-day habits of engineering teams — not just in how code is written, but in how work is planned, how requirements are handled, how quality is managed, and how teams communicate. What follows covers some of the most common and highest-impact areas, though Lean practice extends well beyond this list.
Planning and intake
Lean teams limit what enters the system to what the team can actually absorb. Backlogs are not unlimited queues of everything anyone has ever requested — they are prioritised, regularly pruned, and sized to capacity. Work is not started unless the team has the bandwidth to finish it. Planning conversations ask not just "what do we build next?" but "should we build this at all, and is now the right time?"
Requirements and design
Lean pushes for clarity before work starts, not after. Ambiguous requirements are one of the most expensive waste types — a team that builds the wrong thing for six weeks and then reworks it has wasted far more than the time spent clarifying upfront. Short written specifications, quick design reviews, and early conversations between developers and stakeholders all reduce the cost of misunderstanding before it compounds.
Development habits
Small batches are the central habit. Trunk-based development keeps integration continuous — long-lived branches accumulate debt and merge as large, risky batches. Frequent small commits mean each change is visible, testable, and reviewable immediately. Work is finished before new work is started, because partially done work is waste.
Testing and quality
Lean treats quality as something built in at every step, not checked at the end. Automated tests run on every commit. Developers write tests alongside code, not after. When a bug is found, the first question is not just how to fix it but how the system allowed it to reach this stage — and what can be changed to catch it earlier next time.
Code review
Reviews are flow mechanisms, not gatekeeping rituals. Small pull requests reviewed quickly keep the queue short and the feedback immediate. Large PRs that sit for days are a symptom of batch size problems and review-as-bottleneck culture. Lean teams treat a PR sitting unreviewed for more than a day as a queue problem worth solving.
Deployment and release
Lean teams deploy frequently and in small increments. Infrequent large releases concentrate risk, make rollbacks difficult, and delay the feedback that only production provides. Continuous delivery — the capability to release any commit safely at any time — is the technical expression of the "deliver as fast as possible" principle.
Reducing process overhead
Every approval gate, status meeting, and hand-off step that does not add value is waste. Lean teams regularly audit their own processes: which ceremonies are generating insight, and which are consuming time without return? Approvals that exist because they always have, status updates that duplicate information already visible on the board, and sign-off chains inherited from a different era are all candidates for elimination.
Observability and feedback
Lean requires fast feedback from production, not just from development. Teams invest in logging, monitoring, and alerting so that problems surface quickly after deployment. Without observability, small batches and frequent releases create risk rather than reducing it — the team cannot see what is happening. With it, fast delivery becomes genuinely safe.
One prerequisite applies across all of these: a technical foundation that supports them. Small batches require the ability to deploy safely — automated testing, reliable pipelines, sufficient observability. Teams on brittle codebases or manual release processes will find Lean practices hard to sustain. Building that foundation is itself a Lean act — it is waste removal that enables everything else.
Where to Start
Lean can feel overwhelming when encountered as a complete system. The steps below are not a complete implementation programme — they are a starting point. In practice, the entry point is simple: make the work visible, then follow the problems.
Step 1: Map one piece of work. Pick a feature that recently shipped and walk it backwards. When was it first requested? When did work actually start? Where did it wait, and for how long? Do this for three or four items. Patterns will emerge — a review queue that consistently adds days, an approval step that nobody questions, a dependency that always blocks. That is your value stream, and those waiting periods are your first improvement targets.
Step 2: Visualise active work. Create a shared board with columns that reflect how work actually moves — not how you wish it moved. Include every stage from "ready to start" to "in production." Put every active item on it. The board will immediately reveal how much partially done work is in the system, and where it is accumulating.
Step 3: Count the work in progress. Before setting any WIP limits, simply count. How many items are actively in development right now? In review? Most teams are surprised by the number. If a developer has five active items, task switching is costing more than anyone realises. If the review column has twelve items, that queue is the bottleneck regardless of how fast code is being written.
Step 4: Introduce one limit. Pick the stage with the most accumulation and set a WIP limit — a number slightly below what is currently there. Not a rule imposed from above, but an experiment the team agrees to try for two weeks. The discomfort that follows is informative: it surfaces exactly where the real constraint is.
Step 5: Shorten one feedback loop. Look at the practices section and pick one. If PRs are large and slow to review, introduce a team norm around smaller pull requests. If the test suite is slow, treat speeding it up as the next sprint's priority. If requirements arrive unclear, introduce a short written clarification step before development starts. One change at a time, observed carefully.
The goal of these steps is not to implement Lean — it is to start seeing the system. Once the waste is visible, the improvements suggest themselves.
Beyond these first steps, the ongoing practice is this: continuously observe what the team and organisation actually do, and ask honestly what is necessary and what can be cut. For every activity that remains, ask which type of waste it might be creating and how it could be reduced. That is kaizen — and it has no end point.
Conclusion: Lean as a Lens
Lean is not a process to follow. It is a lens for understanding a system.
Through that lens, you stop seeing a collection of teams doing their jobs and start seeing a system — with queues building at handoffs, waste accumulating in the gaps between stages, and structural conditions preventing value from flowing that no individual team has the authority or visibility to fix on their own.
That reframing changes where improvement effort goes. Instead of asking how to make developers faster, you ask where work is waiting. Instead of measuring how busy teams are, you measure how long value takes to reach users.
Here is what most organisations discover when they start looking: the capacity for better delivery was already there. It was just buried under waste — under partially done work, unnecessary process, decisions made too late, and work that should never have been started. Removing that waste does not require more people or more budget. It requires seeing the system clearly and changing it deliberately. The efficiency gains are not created from nothing — they are recovered from what was being lost.
That, at its core, is the promise of Lean. Not a framework to adopt, but a way of seeing — and a discipline of continuously improving what you see.
About N Sharma
Lead Architect at StackAndSystemN Sharma is a technologist with over 28 years of experience in software engineering, system architecture, and technology consulting. He holds a Bachelor’s degree in Engineering, a DBF, and an MBA. His work focuses on research-driven technology education—explaining software architecture, system design, and development practices through structured tutorials designed to help engineers build reliable, scalable systems.
Disclaimer
This article is for educational purposes only. Assistance from AI-powered generative tools was taken to format and improve language flow. While we strive for accuracy, this content may contain errors or omissions and should be independently verified.