Learning Paths
Last Updated: March 19, 2026 at 17:30
Onion Architecture: Structuring Your Software Around the Core Domain
How concentric layers with inward-pointing dependencies protect your business logic and enable domain-driven design
Onion Architecture provides a framework for building software systems that revolve around the business domain rather than technical concerns, ensuring that core logic remains protected from external dependencies like databases and frameworks. By structuring code in concentric layers, with the domain entities at the center, developers can enforce inward-pointing dependencies, improve testability, and maintain long-term flexibility. This tutorial explores the emergence of Onion Architecture, explains its layered domain model, demonstrates dependency inversion in action, and compares it to Clean Architecture and Hexagonal Architecture. Through detailed examples from financial and enterprise applications, we'll examine the practical benefits, implementation strategies, and common pitfalls. By the end, you'll understand not just what Onion Architecture is, but how to apply it effectively in your own systems
Introduction
Most software systems start simple. A handful of features, a database, some business rules — and it all fits together cleanly. But as systems grow, something starts to go wrong. Business logic becomes tangled with database code. Framework updates force changes in places that have nothing to do with the framework. A developer trying to understand a core rule finds themselves wading through layers of infrastructure before they can even locate it.
This is the problem Onion Architecture was designed to solve. Introduced by Jeffrey Palermo in 2008, it offers a way to organise software so that the most important part — the business domain — remains protected, stable, and easy to understand, regardless of how the surrounding technology evolves.
This article explains what Onion Architecture is, how each of its layers works, why its rules matter, and when you should (and shouldn't) reach for it.
Why the Problem Matters
Before exploring the solution, it's worth understanding what goes wrong without it.
In traditional layered architectures, dependencies typically flow downward: the user interface depends on the application logic, which depends on the domain, which depends on the database layer. This seems logical at first — you build from the top down, and data flows through the layers.
But there's a hidden problem buried in this arrangement. The domain layer — the part of the system that represents your core business rules — ends up depending on the database layer. This means your most valuable code, the code that expresses what your business actually does, is coupled to one of the most changeable parts of the system: infrastructure.
Change your database? Your domain might break. Upgrade your ORM framework? Your business rules may need to be rewritten. Bring a domain expert in to review the logic? They can't read it, because it's buried under framework annotations and SQL queries.
The coupling between business logic and technical infrastructure is the root of the problem. Onion Architecture breaks that coupling.
The Central Idea: Dependencies Always Point Inward
The defining rule of Onion Architecture is simple to state: dependencies always point inward, toward the domain core, and never outward.
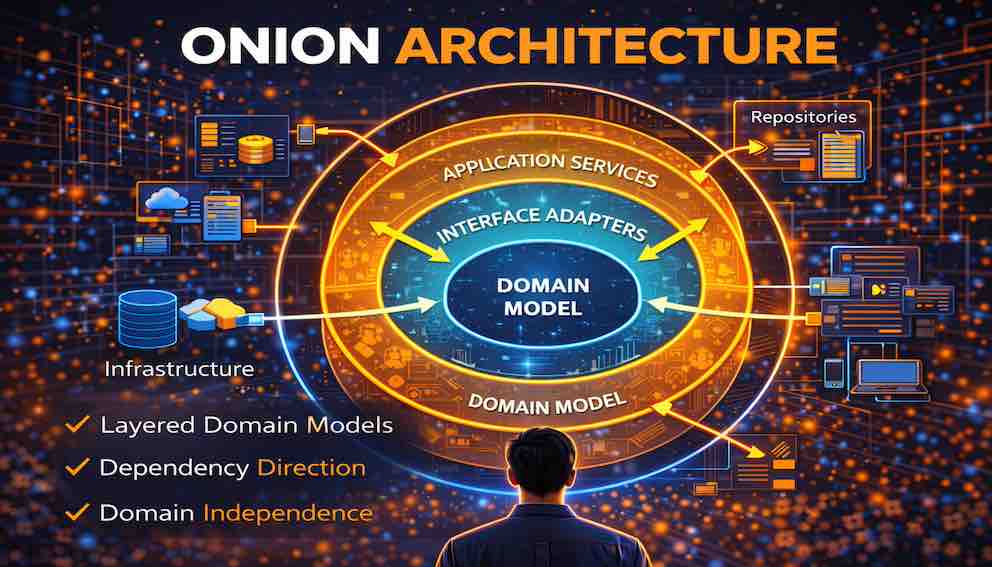
Imagine the system as a series of concentric rings, like the cross-section of an onion. At the very centre is the domain — the pure business logic of the application. Surrounding it are layers of increasing technical concern: first domain services, then application services, then infrastructure. Each outer layer knows about the layers inside it, but the inner layers know nothing about what lies outside.
This means the domain core has zero knowledge of databases, web frameworks, messaging systems, or external APIs. It exists in isolation, expressing business rules in plain language, unburdened by technical concerns. Everything else — every concrete implementation, every database call, every HTTP request — wraps around the outside and conforms to what the domain needs.
This inversion of the typical dependency direction is what makes the architecture powerful. The most stable, most valuable part of the system no longer depends on the most volatile part. Infrastructure depends on the domain, not the other way around.
The Layers of the Onion
Layer 0: Domain Entities — The Core
At the very heart of the onion are the domain entities. These represent the fundamental concepts of the business and contain the rules that must always hold true.
It's important to understand what entities are not: they are not simple data containers with fields and accessors. An entity in Onion Architecture encapsulates behaviour. It enforces its own invariants. It expresses the rules of the domain in a way that is readable and verifiable.
In a payments system, for example, a Payment entity would not just hold an amount and a status — it would enforce that a payment can only be completed if it's currently pending, or that a refund is only possible on a completed payment. These rules live inside the entity itself, not in a service or a controller somewhere else.
The crucial constraint is that domain entities have no dependencies on external systems. No database annotations. No framework imports. No references to HTTP, messaging, or persistence. They are pure business logic, written in the language of the domain. They could, in theory, run entirely in memory, and that is exactly what makes them so easy to test.
Good domain entities are the kind of code a domain expert could sit beside a developer and read through together, understanding every rule without needing to know anything about the underlying technology.
Layer 1: Domain Services
Sometimes, business logic doesn't fit naturally inside a single entity. It might involve coordinating rules across multiple entities, or it might describe a process that spans several concepts. This is the role of domain services.
Domain services live in the core of the onion, alongside entities. They are still pure business logic — no database calls, no external API calls, no framework dependencies. But they handle the cases where a rule is too complex or too broad for any single entity to own.
A loan eligibility check, for instance, might need to look at a customer's credit score, their debt-to-income ratio, their employment history, and the size of the requested loan. None of those pieces of logic belongs solely to the customer entity or the loan entity. A domain service can draw them together and express the eligibility rule as a coherent business concept.
The key characteristic of a good domain service is that it operates entirely in terms of domain concepts. It reasons about customers, loans, payments, and policies — not about rows, records, endpoints, or messages.
Layer 2: Application Services
Moving outward from the core, we reach the application services layer. If the domain entities and services represent what the rules are, application services represent how a specific use case is carried out.
Application services coordinate the domain. They load entities from repositories, invoke domain services, pass results to external systems through defined interfaces, and persist the outcomes. They are the conductors of the orchestra — they don't play the instruments themselves, but they direct the overall performance.
An application service handling a loan application, for example, might: retrieve the customer, run the eligibility check, request a credit report from an external bureau, create a loan entity if everything passes, and save the result. Each of those steps either delegates to the domain (for business rules) or to an interface (for infrastructure).
Application services define what the system does without caring about how the underlying systems work. They depend on interfaces — abstractions for repositories and external services — but they never depend on concrete implementations. Those implementations live in the outermost layer.
Layer 3: Infrastructure
The outermost layer is infrastructure: databases, ORMs, external APIs, messaging systems, web frameworks, and everything else that connects the application to the outside world.
This is where concrete implementations live. The database repository that fulfils the repository interface defined in the application layer. The Stripe integration that fulfils the payment gateway interface. The REST controller that translates HTTP requests into application service calls.
Infrastructure knows about the inner layers — it must, in order to implement their interfaces. But the inner layers know nothing about infrastructure. The domain doesn't know whether its entities will be stored in PostgreSQL, MongoDB, or an in-memory cache. It doesn't care. That's infrastructure's concern, and infrastructure is free to change without disturbing the domain.
How Dependency Inversion Makes It Work
The mechanism that holds Onion Architecture together is the Dependency Inversion Principle. Rather than the domain directly calling a database, the domain defines an interface — an abstract specification of what it needs — and the infrastructure provides a concrete implementation of that interface.
The domain says: "I need something that can find a customer by their ID and save a new loan." It expresses that need as an interface. It doesn't know, and doesn't need to know, how that capability is fulfilled.
The infrastructure layer then provides the implementation: a JPA-backed repository, or a document store adapter, or a simple in-memory store for tests. The domain never changes regardless of which one is plugged in.
This is the practical expression of the inward-dependency rule. By depending on abstractions rather than concrete classes, the inner layers remain insulated from infrastructure detail, and the infrastructure can be swapped, upgraded, or replaced independently.
The Relationship to Domain-Driven Design
Onion Architecture and Domain-Driven Design (DDD) are natural companions. Palermo designed Onion Architecture with DDD principles in mind, and the two approaches reinforce each other strongly.
DDD encourages developers to build a rich model of the business domain — one expressed in the ubiquitous language that both developers and domain experts share. Onion Architecture provides the structural container that lets that model flourish.
When entities are isolated from infrastructure, the ubiquitous language can be expressed clearly in the code. There's no framework noise obscuring the business rules. A domain expert can sit with a developer and read through the core layer, recognising the concepts and validating the logic. That kind of shared understanding is the heart of DDD.
DDD's tactical patterns fit naturally into the layers: entities and value objects belong in the core, aggregates define consistency boundaries there too, repository interfaces live in the domain or application layer, and domain events can be defined in the core and dispatched through infrastructure interfaces. Each piece finds a natural home.
How Onion Architecture Relates to Clean Architecture and Hexagonal Architecture
Readers familiar with Clean Architecture (Robert C. Martin) or Hexagonal Architecture (Alistair Cockburn) will recognise the same family of ideas at work.
All three architectures share the same foundational principles: protect the domain from infrastructure, enforce inward-pointing dependencies, use abstraction to invert dependencies, and improve testability by isolating business logic.
The differences lie mostly in emphasis and terminology. Clean Architecture organises the system around use cases as the primary unit of structure, giving them a prominent layer of their own. Hexagonal Architecture uses the metaphor of ports and adapters, emphasising that the application should be equally driveable from any direction — a web UI, a command line, a test harness — all treated as interchangeable adapters. Onion Architecture places the domain model itself at the centre and emphasises the hierarchy of domain layers as the organising principle.
In practice, experienced architects often blend ideas from all three. The terminology matters less than the principles. If your system has a stable, well-isolated domain core with dependencies pointing inward, you're working in the spirit of all three approaches.
Why Testability Improves So Dramatically
One of the most immediate and measurable benefits of Onion Architecture is the effect it has on testing.
When business logic is tangled with infrastructure, tests become expensive. To test a single business rule, you might need a running database, a live network connection, a configured framework context, and a dozen lines of setup code. Tests like these are slow, fragile, and difficult to maintain.
When the domain core has no dependencies on infrastructure, tests become simple. An entity can be instantiated, given some inputs, and tested completely in isolation — in pure memory, in milliseconds, with no setup required. Domain services can be tested with real entity instances rather than mocks. Application services can be tested using in-memory implementations of their interfaces rather than real databases.
The result is a fast, reliable test suite that developers can run constantly and trust fully. This kind of test coverage gives teams genuine confidence when changing code — confidence that is hard to achieve when tests require infrastructure to run.
Advantages of Onion Architecture
When applied consistently, Onion Architecture delivers several lasting benefits:
Stable business logic. Your most valuable code — the domain — is protected from infrastructure changes. Switching databases, upgrading frameworks, or replacing external services doesn't require touching the core.
Excellent testability. As described above, the core can be tested in complete isolation, leading to fast, reliable suites.
Clear structure. Each layer has a defined responsibility. Developers always know where business rules belong, where use case orchestration belongs, and where infrastructure concerns belong. This clarity reduces cognitive load and makes onboarding easier.
Natural alignment with DDD. The architecture provides an ideal structural home for rich domain models, ubiquitous language, and DDD tactical patterns.
Long-term maintainability. As the system evolves over years, the core remains stable. Technologies around it can be modernised without destabilising the business logic.
Technology independence. The domain doesn't depend on any particular database, framework, or external service. Business rules can outlive any technology choice made at the start of the project.
Challenges and Trade-offs
Onion Architecture is not without costs. Understanding the trade-offs honestly helps teams make the right architectural decisions.
More upfront structure. The architecture requires more code at the start: interfaces, mapping code between layers, and carefully separated concerns. For small or simple projects, this can feel like unnecessary overhead.
Learning curve. Developers unfamiliar with dependency inversion, interface design, and layered boundaries need time to learn the approach before they can apply it confidently.
Slower initial velocity. In the earliest stages of a project, building abstractions before you know you need them can feel like over-engineering. The architecture trades short-term speed for long-term maintainability — a worthwhile trade for complex, long-lived systems, but not always the right one.
CRUD complexity. For simple create-read-update-delete operations with no meaningful business logic, Onion Architecture can impose significant ceremony for very little benefit.
Discipline required. The architecture only works if the team consistently maintains the dependency rule. Violations — a domain entity acquiring a database annotation, an application service bypassing an interface — accumulate over time and degrade the architecture. This requires active attention and code review.
Mapping overhead. Data often needs to be transformed as it crosses layer boundaries. Domain objects become persistence entities become response DTOs. This mapping work is real, though tools and frameworks can reduce the burden.
The Risk of Anemic Domain Models
One pitfall deserves special attention because it's so common and so insidious.
It's entirely possible to implement all the layers of Onion Architecture correctly — the right packages, the right interfaces, the right dependency directions — and still end up with a poorly designed system. This happens when entities become simple data bags with no behaviour, and all the business logic ends up in application services.
This is known as an anemic domain model, and it defeats the core purpose of the architecture. If your entities have no behaviour, you've spent a lot of effort on structure without getting the benefit of a protected, expressive domain.
The test is simple: can a domain expert read your domain layer and recognise the business rules? If the core is just fields and getters, and the rules are scattered through application services, the architecture is there in name only. Real Onion Architecture requires genuine investment in modelling the domain richly.
When Onion Architecture Is the Right Choice
Good fits:
Complex business domains. When the system contains valuable, intricate business rules that will evolve over time, isolating them in a protected core pays sustained dividends.
Long-lived enterprise systems. For systems that will run and grow over many years, the investment in clean boundaries keeps the codebase maintainable as teams and technologies change.
Domain-Driven Design projects. If the team is using DDD to model a rich domain, Onion Architecture provides exactly the structural support DDD needs.
Multiple integration points. When the application connects to many external systems, keeping those connections at the outer edge prevents integration complexity from leaking into the core.
Poor fits:
Simple CRUD applications. If there's minimal business logic and the system is mostly data entry and retrieval, the overhead of Onion Architecture outweighs its benefits.
Prototypes and MVPs. When the goal is rapid validation of an idea, architectural purity is a distraction. Build simply, prove the concept, and refactor if the system is worth investing in.
Teams without architectural maturity. If the team is still developing foundational skills, the concepts behind Onion Architecture can overwhelm rather than help. Build the skills before applying the pattern.
Practical Tips for Implementation
Make the architecture visible in your package structure. Organise your code so that the layers are immediately apparent to any developer who opens the project. A domain package containing model and service sub-packages, an application package for use-case services, and an infrastructure package for persistence and external adapters communicates the architecture before a single line of code is read.
Define interfaces where they're consumed, not where they're implemented. Repository interfaces belong in the domain or application layer — not in the infrastructure layer. The inner layer specifies what it needs; the outer layer provides it.
Use simple, framework-agnostic objects at layer boundaries. Don't pass ORM entities or HTTP request objects into application services. Create dedicated, plain objects for each use case: a command object going in, a result object coming out. This keeps the application services insulated from framework changes.
Wire dependencies at the composition root. Assemble the object graph at the application's entry point, typically using a dependency injection container. Keep the wiring separate from the domain and application logic.
Conclusion: Architecture as Protection of Value
Onion Architecture is, at its core, a philosophy about what matters most in a software system. Business logic — the rules that reflect what an organisation does and how it operates — is the most valuable part of any application. It's the part that took years to understand, that domain experts spent careers refining, that differentiates the system from any off-the-shelf alternative.
Technical infrastructure — the databases, the frameworks, the message queues — is important, but it's also transient. Databases get replaced. Frameworks go out of fashion. APIs change. The infrastructure of today is not the infrastructure of five years from now.
Onion Architecture asks a simple question: if your infrastructure will change, why should your business logic depend on it? By placing the domain at the centre and having everything else depend on it — rather than the reverse — you build a system where the most valuable part is also the most protected.
The name is fitting. Like an onion, the outer layers wrap around and protect what's inside. Peel them away and the core is still intact, still whole, still the thing that gives the onion its character.
For teams building complex systems that will need to grow and adapt over time, that protection is not a luxury — it's the entire point.
Key Takeaways
- Onion Architecture organises software into concentric layers with the domain at the centre and all dependencies pointing inward.
- The outermost layers — infrastructure — depend on the inner layers, never the reverse.
- Domain entities at the core contain business rules and invariants expressed in pure code, with no dependency on any framework or infrastructure.
- Domain services handle business logic that involves multiple entities or processes too broad for a single entity to own.
- Application services orchestrate use cases by coordinating domain objects and calling infrastructure through interfaces.
- Infrastructure implements the interfaces defined by inner layers, providing concrete access to databases, external APIs, and other systems.
- Testability improves dramatically because the core can be exercised entirely in memory, with no infrastructure required.
- The architecture aligns closely with Domain-Driven Design and shares foundational principles with Clean Architecture and Hexagonal Architecture.
- Common pitfalls include anemic domain models, infrastructure leaking into the core, and architectural drift from lack of discipline.
- The pattern fits best in complex, long-lived systems with rich business logic, and least well in simple CRUD applications or prototypes.
- Architecture is ultimately about protecting value — ensuring that the most important business logic remains stable and maintainable as the technology around it evolves.
About N Sharma
Lead Architect at StackAndSystemN Sharma is a technologist with over 28 years of experience in software engineering, system architecture, and technology consulting. He holds a Bachelor’s degree in Engineering, a DBF, and an MBA. His work focuses on research-driven technology education—explaining software architecture, system design, and development practices through structured tutorials designed to help engineers build reliable, scalable systems.
Disclaimer
This article is for educational purposes only. Assistance from AI-powered generative tools was taken to format and improve language flow. While we strive for accuracy, this content may contain errors or omissions and should be independently verified.