Learning Paths
Last Updated: April 24, 2026 at 14:00
Monolith vs Microservices vs Modular Monolith: Choosing the Right Architecture
A detailed comparison of three architectural approaches — including trade-offs in team structure, deployment, scalability, and maintainability — with a practical decision framework
Not sure whether to start with a monolith or microservices? This guide compares all three architectural approaches side by side. You will learn what a modular monolith is and why it might be the compromise you have been looking for, how the trade-offs play out across team structure, deployment, and scalability, and how to use a practical decision framework on your own project. We will also look at how architectures evolve over time — because you rarely need to get this decision perfect on day one
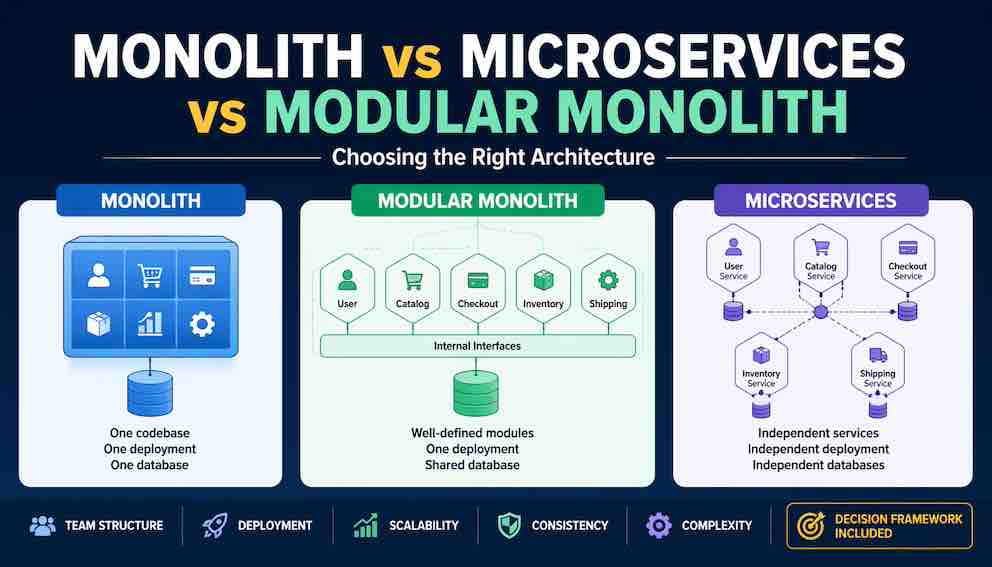
The scenario that forces a choice
You are starting a new e-commerce platform. Three developers on the team. Four months to launch.
You sit down to design the system. Someone suggests microservices because Netflix uses them. Someone else says a monolith is faster to build. A third person mentions something called a "modular monolith" that nobody has heard of before.
What do you choose?
The honest answer is: it depends on things you cannot fully know yet — how many users you will get, how your team will grow, what features will come later. But you can make a well-reasoned choice right now by understanding what each approach actually involves and what it will cost you as your project grows.
The traditional monolith
You can recognise a monolith by looking at its deployment. Everything runs as a single process. One codebase. One database. One deployable artifact.
In an e-commerce monolith, all the code for user accounts, product catalogue, shopping cart, checkout, payments, inventory, and shipping lives in one application. When a user visits the website, that single application handles every request. When you deploy a new version, you replace the entire application at once.
You might organise the code internally into modules or packages — and you should — but at runtime, it is one process.
Where a monolith shines
Small teams. For a small team of developers, a monolith keeps coordination simple. Everyone works in the same codebase. Everyone sees the same deployment process. There is very little overhead getting things done.
Simple deployments. You have one artifact to build, one place to configure, one process to monitor. Operations is about as straightforward as it gets.
Strong consistency. With one database, you can use ACID transactions. Update inventory and create an order in the same transaction. If anything fails, nothing changes. This kind of correctness is something distributed systems have to work hard to replicate.
Fast local development. One command starts everything. No network calls between components. Debugging is simple — you can step through the entire request in one place.
Lower overhead. No service discovery. No distributed tracing. No API versioning between internal components. You just write code.
Where a monolith hurts
As the application grows, some predictable pain points emerge.
Long build and test times. A small change triggers a full rebuild and the entire test suite. Waiting thirty minutes to verify a one-line fix is demoralising, and it slows everyone down.
Scaling inefficiency. You cannot scale just the checkout feature during a Black Friday sale. You scale everything, paying for compute you do not need.
Technology lock-in. You chose Java three years ago. Now you want to try a faster language for one performance-critical component. In a monolith, that may not be feasible.
Fragile coupling. A bug in the promotional banner code can crash payment processing because everything runs in the same process. When one thing fails, everything can fail with it.
Team friction. Two teams need to change different parts of the same codebase at the same time. Merge conflicts, release coordination, waiting for each other — all of this slows down delivery as the team grows.
The modular monolith
This approach is less famous than the other two, but it may be the practical choice for many small teams.
A modular monolith is a single deployed application where the code is organised into strongly separated modules. Each module has well-defined boundaries and communicates with other modules through explicit interfaces — not by reaching directly into each other's internals or database tables. At runtime, however, everything still runs in one process.
The key idea here comes from domain-driven design: you identify the distinct areas of your business (the bounded contexts), and you mirror those boundaries in your code. The checkout module handles the checkout flow. The inventory module manages stock levels. The user module handles accounts and authentication. The catalogue module manages products and categories. Each exposes a public interface that other modules can call, but its internal implementation is its own business.
This distinction — enforced interfaces between modules, even within a single application — is what separates a modular monolith from a monolithic application sometimes called a big ball of mud. It is also worth noting that this boundary enforcement does not happen automatically. You need discipline, code reviews, and ideally automated tools that can fail a build if one module reaches directly into another's internals.
Where a modular monolith shines
Strong separation without network complexity. You get clean boundaries between parts of your system, but you avoid the pain of network calls, serialisation, and distributed failures. Calling the inventory module from checkout is just a function call.
Single deployment, organised code. One artifact to deploy, but the structure is sound enough that you can later split individual modules into microservices without a complete rewrite.
Transactional consistency across modules. Because everything runs in one database (or one transaction scope), you can maintain strong consistency across module boundaries when you need it — something microservices cannot offer without significant complexity.
Easier refactoring than microservices. Changing a module's interface is simpler than changing a service API. You do not need to coordinate deployments across multiple teams and repositories.
Low operational overhead. One application to monitor. One log file. No service discovery. No distributed tracing required. If you are a small team, this frees up a lot of time to focus on the product.
Where a modular monolith hurts
Single point of failure. A bug in any module can still crash the entire application. You do not get the failure isolation that microservices provide.
Scaling remains all-or-nothing. You still cannot scale the checkout module independently. If checkout needs more resources under load, the whole application gets more resources.
Team coordination still needed. Different teams can own different modules, but they must coordinate on deployments. Team A cannot release their module changes without redeploying Team B's modules at the same time.
Discipline is required. The separation between modules is enforced by conventions and tooling, not by network boundaries. A developer can violate module boundaries if they choose to — or simply if nobody has set up the automated checks. Maintaining the structure requires ongoing effort.
Microservices
Each business capability becomes its own independently deployed service. The checkout service runs separately from inventory, which runs separately from user accounts. Each service has its own database. Services communicate over the network using REST, gRPC, or message queues.
To deploy a change to the checkout service, you rebuild and redeploy only the checkout service. The other services continue running unchanged.
Where microservices shine
Independent deployability. Change one service, deploy one service. No coordination with other teams required at release time. This is the defining benefit that everything else flows from.
Independent scaling. Scale only what needs scaling. If checkout is hammered during a sale but the product catalogue is fine, you scale just checkout. Your cloud bill reflects actual usage patterns rather than worst-case assumptions.
Technology freedom. Each service can use the best language and framework for its job. One service might be Python for data processing, another Go for high-throughput APIs.
Team autonomy. Each team owns their services end-to-end — they build, deploy, monitor, and operate what they build. This aligns well with Conway's Law, which observes that systems tend to mirror the communication structure of the teams that build them. If you want independent services, organise into independent teams.
Failure isolation. If the checkout service crashes, the product catalogue keeps working. A single bug does not bring down the whole system.
Where microservices hurt
Distributed system complexity. Network calls fail in ways that in-process function calls do not. Latency is unpredictable. Partial failures are hard to handle gracefully. You need to think about retries, timeouts, circuit breakers, and what to show the user when one of five services is down.
Operational overhead. Twenty services mean twenty monitoring dashboards, twenty log sources, twenty sets of configuration, twenty sets od CI/CD pipelines, and a container orchestrator like Kubernetes to manage them all. This is real work.
Data consistency challenges. There are no distributed transactions across services. Instead, you use patterns like the Saga pattern — where a multi-step operation across services is broken into a chain of local transactions, each triggering the next, with compensating actions if something fails partway through. It works, but it is significantly more complex than a simple database transaction.
End-to-end testing complexity. Testing a user flow that spans five services requires all five services to be running, each possibly at different versions, with coordination between their test environments.
Developer experience overhead. Running twenty services locally can strain your laptop.
How the three approaches compare
Let us walk through each important dimension and understand how the approaches differ in practice.
Deployment
A monolith is one artifact deployed to one process. Simple, but all-or-nothing — every change, no matter how small, requires a full redeployment of everything.
A modular monolith shares the same deployment simplicity. One artifact, one process. The internal structure is better, but the deployment story is identical.
Microservices are many artifacts deployed to many processes. Each can be changed and deployed independently, but the coordination and infrastructure required to manage that is substantial.
Team structure
Monoliths work best with one team working on the whole codebase. Multiple teams can collaborate, but they will feel the friction of shared ownership fairly quickly.
In a modular monolith, multiple teams can each own different modules. But they must still coordinate on deployments — there is one shared release that all modules travel in together.
Microservices are where teams can genuinely operate independently. Each team owns one or more services and deploys on their own schedule. Coordination happens through API contracts, not deployment calendars.
Scalability
With a monolith or modular monolith, you scale everything or nothing. Your checkout feature and your static product pages get the same resources whether they need them or not. Simple to manage, but inefficient at scale.
With microservices, you scale individual services based on their actual load patterns. This is more cost-efficient and more precise, but it requires more configuration and infrastructure to achieve.
Data consistency
Monoliths and modular monoliths (assuming shared or carefully partitioned databases) offer strong ACID transactions. You can update multiple tables atomically. If anything fails, the whole operation rolls back cleanly.
Microservices trade this for independence. Each service has its own database, so strong consistency only exists within a single service's boundaries. Cross-service operations rely on eventual consistency — the data will be correct eventually, but there may be a brief window where things are out of sync. For many applications this is fine; for financial systems or inventory with strict correctness requirements, it requires careful design.
Development speed
Early in a project, monoliths and modular monoliths are significantly faster. No infrastructure complexity. Simple tooling. You just write business logic.
Microservices are slow to get started with. Before you write meaningful business logic, you need service discovery, container tooling, API gateways, and distributed tracing. This overhead can cost weeks.
Later in a large project, the picture changes. Monolith build times grow. Tests take longer. Merge conflicts multiply. Modular monoliths hold up better than unstructured monoliths due to their clearer boundaries, but they still face the same build and deployment constraints. Microservices, by contrast, let each service stay small and focused — individual services remain fast to build and test even as the overall system grows.
Failure isolation
Monoliths and modular monoliths offer no runtime isolation. A crash in one feature can crash everything. You can mitigate this with good error handling, but the risk is always there.
Microservices offer genuine isolation. One service crashing does not take down the others. Combined with circuit breakers and graceful degradation, this enables significantly higher system resilience.
Operational complexity
Monoliths are the simplest to operate — one process, one log file, simple health checks.
Modular monoliths are similar, though you might add module-level metrics to understand where performance issues originate.
Microservices are the most complex to operate. You need service discovery, distributed tracing, log aggregation, metrics collection, alerting across many services, and a deployment pipeline for each. This is not a reason to avoid microservices, but it is a cost that needs to be budgeted for honestly.
A decision framework you can apply
Work through these questions in order. The first answer that applies is usually sufficient.
Question 1: How large is your team?
If your team has low number of developers, start with a monolith or modular monolith. Microservices add coordination overhead that a small team cannot afford. Your priority is to ship software, not manage infrastructure.
If you have as mid size team, a modular monolith is a strong choice. You can organise into sub-teams that each own modules. If you outgrow it, you can split specific modules into microservices later without starting from scratch.
If your team has several developers, microservices start to justify their complexity. The coordination cost of a shared monolith at this size is enormous. Independent deployability stops being a nice-to-have and starts feeling like survival.
Question 2: Do you need independent scaling for different parts of the system?
If certain features have wildly different traffic patterns — checkout spikes on Black Friday but the product catalogue is steady — microservices let you scale each independently.
If your traffic patterns are relatively uniform, or if you can simply over-provision a monolith without it being financially painful, the scaling argument for microservices is weak.
Question 3: Can you tolerate eventual consistency?
If your application needs strong transactional correctness across all operations — financial ledgers, inventory systems, anything where "eventually consistent" is not good enough — a monolith or modular monolith keeps this simple. Distributed transactions are possible in microservices but are genuinely hard to get right.
If eventual consistency is acceptable — which covers a large proportion of web applications — microservices become viable from a data perspective.
Question 4: What is your operational maturity?
Does your team have experience running distributed systems? Do you have automated deployment pipelines? Do you have monitoring and alerting that works reliably?
If the answer to any of these is no, start with a monolith or modular monolith. Microservices will expose and amplify weaknesses in your operations. Better to build operational maturity while running a simpler system, then migrate when you are ready.
Question 5: Is this an MVP or a well-understood domain?
If you are building a minimum viable product, choose a monolith. Speed to market matters more than architectural purity at this stage. You can refactor later — and you very likely will, because the product will change significantly once real users start using it.
If you understand the domain deeply from day one and can identify clear domain boundaries with confidence, a modular monolith makes sense from the start.
A recommendation you can follow
For most projects — especially those without clear evidence that a monolith will fail — start with a modular monolith.
Here is why: you get clean boundaries from the beginning, which makes future decomposition straightforward. You avoid the operational complexity of microservices until you actually need it. You maintain strong consistency and simple deployments. And when you succeed and grow, you can split individual modules into microservices incrementally, one at a time, based on real evidence of need.
This hybrid approach — a modular monolith with one or two extracted microservices where the need is clear — is more common than pure microservices architectures in the real world.
The key is to start with modular thinking. Design clear module boundaries based on business capabilities. Use well-defined interfaces between modules. Keep each module's database tables clearly owned by that module, even if they share a physical database for now. This discipline upfront is what makes future extraction tractable.
How architectures evolve
No architecture is permanent. The typical path looks something like this.
Stage 1 — Monolith. You build the first version quickly. You learn about the domain. You validate the product with real users.
Stage 2 — Modular monolith. The monolith grows. You refactor to introduce module boundaries. Teams begin to form around those modules.
Stage 3 — First extracted microservice. One module becomes a bottleneck. It needs to scale independently, or its team wants faster release cycles. You extract it into a microservice, leaving the rest as a modular monolith.
Stage 4 — Selective extraction. Over time, a few more modules are extracted. You end up with a core modular monolith surrounded by purpose-built microservices where the complexity is genuinely justified.
Stage 5 — Full microservices. Only the large applications with genuine independent scaling needs end up here.
The important thing to take from this is that you do not need to predict the final architecture on day one. You can evolve toward microservices as you discover the need.
Transition strategies
When the time comes to extract a microservice from a monolith, there are a few proven approaches.
The strangler fig pattern gradually replaces parts of the monolith with microservices. Requests are routed to either the old monolith or the new service based on feature flags or routing rules. Over time, the monolith shrinks as its functionality is replaced, piece by piece.
Parallel run involves running both the monolith and the new microservice simultaneously for a period. You compare their outputs to verify the new service behaves correctly, then switch traffic over once you are confident.
Anti-corruption layer is a translation layer that sits between the monolith and the new service, converting between the monolith's data model and the new service's model. This protects the new service from being shaped by the monolith's historical assumptions, letting you design it cleanly.
Common mistakes to avoid
Certain mistakes come up repeatedly when teams navigate these decisions.
Starting with microservices from day one for an MVP. You add weeks of infrastructure work before writing any business logic.
Creating a distributed monolith. This is what happens when teams adopt microservices structurally but not architecturally. The services are tightly coupled — they share databases, require coordinated deployments, and fail together. You end up with all the complexity of microservices and none of the benefits. The root cause is usually a failure to establish clear service boundaries and enforce the database-per-service principle from the start.
Ignoring module boundaries in a monolith. You build a big ball of mud. Later, when you try to extract microservices, there are no clear seams to cut along. The extraction becomes a complete rewrite. Starting with a modular design mindset—even inside a monolith—is a low-cost way to protect yourself from this later.
Adopting architectures based on hype rather than evidence — for example, assuming that because Netflix uses microservices, you should too — is a common mistake. Netflix operates at a level of scale, organisational complexity, and operational maturity that most systems never reach. Architectural choices should be driven by your own constraints, not by what works at extreme scale elsewhere.
Summary
The three approaches sit on a spectrum. A traditional monolith puts everything together in a single deployment — simple to start, but harder to scale and maintain as it grows. A modular monolith enforces strong internal boundaries while remaining a single deployment — clean code without the operational complexity of distributed systems. Microservices go all the way to independent services with independent deployments — maximum flexibility and autonomy, at real infrastructure cost.
The modular monolith is often the overlooked sweet spot. It gives you clean architecture without requiring you to solve distributed systems problems before you have even validated your product. It could be a good place to start. Design clear module boundaries based on business capabilities. Use explicit interfaces between modules. And extract microservices incrementally, only when you have real evidence that a specific module needs the independence.
Most importantly, remember that architectures evolve. The decision you make today does not have to be the decision you live with forever.
About N Sharma
Lead Architect at StackAndSystemN Sharma is a technologist with over 28 years of experience in software engineering, system architecture, and technology consulting. He holds a Bachelor’s degree in Engineering, a DBF, and an MBA. His work focuses on research-driven technology education—explaining software architecture, system design, and development practices through structured tutorials designed to help engineers build reliable, scalable systems.
Disclaimer
This article is for educational purposes only. Assistance from AI-powered generative tools was taken to format and improve language flow. While we strive for accuracy, this content may contain errors or omissions and should be independently verified.