Learning Paths
Last Updated: May 6, 2026 at 16:30
Microservices Decomposition: How Service Boundaries Emerge Using the Five Forces
The five pressures that naturally split your system — and the four reasons you should keep things together even when those pressures exist
Microservices decomposition — deciding where to draw service boundaries — is one of the most valuable skills you can develop in system design. When you get it right, your team deploys independently, failures stay contained, and the system bends without breaking. This article gives you a complete framework for making that decision with confidence. You will learn the five real forces that naturally drive service boundaries, how to recognise the signals that genuinely matter, the four conditions that mean you should keep things together even when forces exist, and the one prerequisite that must be in place before any extraction. By the end, you will know exactly what to look for when someone asks "should this be its own service?" Before you decide where to split your next service, read this.
Before We Begin: What This Article Is and Is Not
This is not a listicle. It is not a set of rules you can apply without thinking. And it is not another "here are the microservices you should build" article.
It is a framework for making one specific decision: when to split a service and when to keep things together. That question comes up on every backend project eventually. Someone asks "should this be its own service?" and the room goes quiet. This article gives you a disciplined way to answer.
The central argument is simple. Service boundaries are not design decisions you make from scratch. They are discoveries. Your system is already under pressure — from data that can no longer be safely shared, from code that changes at different speeds, from failures that cascade where they should be contained. These pressures are forces. Your job is to recognise them, measure them, and decide when they are strong enough to justify the real costs of a network boundary.
You are not splitting services. You are splitting ownership of data, change, and failure.
But forces alone are not enough. You also need to know what is not a force — the false signals that lead teams to extract prematurely. You need to know the situations where even real forces should not lead to extraction. And you need to know the one thing that must exist before you draw any boundary at all: observability.
Here is the full framework: five forces, one prerequisite, a false signal radar, and four disqualifiers. Apply them together.
The Observability Prerequisite: You Cannot Run What You Cannot See
Before you deploy your first service, you need to think about observability. This is not a nice to have. It is a hard gate.
In a monolithic system, when something goes wrong, you have one place to look. One set of logs. One call stack. The path from symptom to cause is linear.
In a distributed system, you lose that linear path. A single user action traverses multiple services, multiple machines, and multiple teams' code. The failure could be anywhere. You do not know. You cannot know without the right instrumentation.
Consider a timeout. The order service thinks it sent a payment request. The payment service has no record of receiving one. Was the request never sent? Was it sent but never received? Was it received but failed silently? Was it successful but the response was lost? In a monolith, these collapse to one explanation. In a distributed system, all four are possible. You cannot distinguish them without three specific things.
Correlation IDs that travel with every request. Structured logs that include those IDs and aggregate across services. Distributed tracing that shows the full call graph for a single request.
Missing any of these is not a follow up task. It is a design flaw. Here is the test. Before you deploy your first service, ask yourself: if this service fails right now, can I determine why within five minutes using the tools I already have? If the answer is no, you are not ready.
Build observability before you deploy. Correlation IDs, structured logs, distributed tracing. Inexpensive to build early. Expensive to retrofit later. Without them, the forces below are irrelevant. You are not ready to run a distributed system.
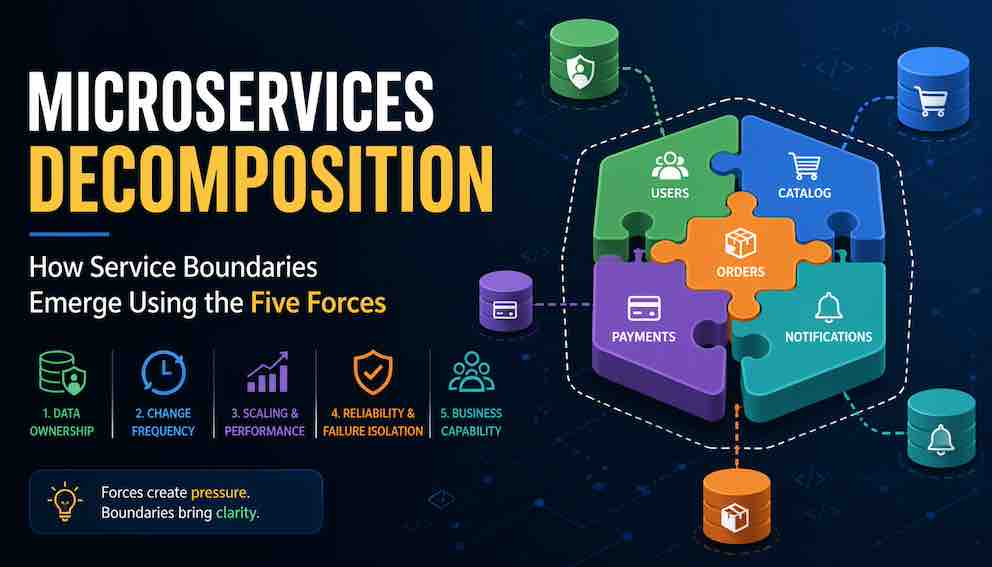
The Five Forces That Define Microservices Boundaries
These are the real pressures that naturally split systems over time. They are not invented by architects. They emerge from the work of building and running software.
Force One: Data Ownership
This is the strongest force in microservices decomposition. If you remember only one force, remember this one.
Systems split when data can no longer have a single, safe point of control.
Here is the first sign. Multiple parts of the system begin writing to the same data. When that happens, every schema change becomes coordination work. The change itself may be simple. But no one can change anything alone. Every adjustment requires talking to other teams, other services, other schedules.
This slows everything down at first. Then it becomes risky.
Here is why shared data is dangerous. It does not fail loudly. It does not throw errors. It does not stop the system. Instead, it drifts. One component changes the meaning of a field. Another component keeps the old assumption. The system keeps running. Everything looks fine. But the data is wrong. Correct in isolation. Incorrect in aggregate.
So data ownership is not really about code structure. It is about authority over meaning. Who is allowed to define what a piece of data represents? Who can change it without asking permission? Who is accountable when that meaning becomes wrong?
Microservices, at their core, are about assigning that authority clearly. You are not splitting code. You are splitting the right to define what data means. Every service boundary is a decision about where data meaning can evolve independently.
So when someone asks "should this be its own service?", the real question is this. Does this data need a single owner to remain correct over time?
If the answer is yes, the system is already under pressure to split. Whether you design it or not.
Most production failures in distributed systems trace back here. Shared tables. Conflicting interpretations of the same field. Services bypassing ownership rules and mutating shared state directly.
Decision rule. If multiple parts of the system write to the same data, or if schema changes require coordination across boundaries, the Data Ownership force is present. This does not automatically mean you must extract a service. But it does mean you already have coupling that will grow unless you make the ownership model explicit.
Force Two: Change Frequency
Parts of the system that change at different rates should live in different places.
This force is often stronger than domain boundaries when you are deciding where to split. Domain boundaries tell you where the business sees separation. That is useful. But change frequency tells you where the system actually hurts. And the system does not care about your org chart.
Here is an example. A promotions engine deploys twice a week. It sits next to an order processing module that deploys twice a month. Every promotions release requires coordination with the order team. The two modules share a deployment unit. The order team has to approve the release window. They have to be available for rollback coordination. They have to worry about whether a promotions change might accidentally break order processing.
This friction is not theoretical. It happens every release.
Now separate the two components. Put them in different services. The promotions team deploys daily with no dependency on the order team. No approval. No rollback coordination. No worry about breaking orders.
The boundary here is not about business logic. It is about change velocity. One part of the system simply moves faster than the parts around it. The friction of that difference becomes unbearable over time.
Decision rule. If a component deploys for reasons unrelated to its neighbours, or if its release cadence consistently differs from adjacent components, the Change Force is present. This alone is a legitimate reason to consider extraction. You do not need a perfect business boundary. You just need different release speeds.
Force Three: Scaling and Performance
Imagine running a search service and a checkout service in the same process. The search service wants to cache everything — give it ten gigabytes of RAM and it will use all of it productively. The checkout service wants none of that. It needs careful transaction handling, strong consistency, and tight resource control. Neither service is wrong about what it needs. They are just fundamentally incompatible roommates.
That incompatibility is what this force is about. When two components have genuinely different resource profiles, deploying them together means one of them is always compromised — either the search service is starved of memory, or the checkout service is sharing infrastructure with something that behaves nothing like it.
But here is the catch. Different resource needs alone is not enough. The difference has to be sustained.
A component that needs fifty times its normal capacity for two hours on Black Friday is not a scaling problem — it is a calendar event. You can handle that by temporarily over-provisioning that component. It is unglamorous, but operating a separate service year-round to solve a two-hour problem is almost certainly more expensive than just throwing some extra capacity at it when you know it is coming.
The Load Force is only real when the higher demand and different resource requirements are the default state, not the exception.
Decision rule. If a component's resource requirements are consistently out of step with everything around it — not occasionally, but as a steady pattern — the Load Force is present. If the difference only shows up during short, predictable spikes, keep things together and over-provision when needed.
Force Four: Reliability and Failure Isolation
In a single deployable unit, failures spread freely. A memory leak in one module affects every module. A slow database query in a reporting feature bleeds into checkout performance. Nothing stops a problem in one corner from becoming a problem everywhere.
Splitting services can fix this — but only if the boundary actually does anything.
Here is the mistake teams make. They split two services, connect them with a synchronous HTTP call, and add no circuit breaker, no timeout, no fallback. Then they are surprised when a failure in the downstream service still takes down the upstream one. They have not contained the failure. They have just put a network hop in front of it.
Picture an order service calling a payment service synchronously. The payment service slows down under load. Without a timeout, every order request now waits. The order service thread pool fills up. Orders stop processing entirely — not because anything is wrong with the order service, but because it is stuck waiting on a dependency it has no protection against.
A service boundary is not a firewall. It is only a failure boundary if you treat it like one. That means circuit breakers that stop calls when the downstream is struggling, timeouts that prevent a slow response from stalling everything behind it, and retries designed carefully enough that they do not turn a small problem into a retry storm.
Decision rule: The Risk Force is present when two things are both true — a failure here would damage unrelated flows, and you are genuinely willing to build the communication patterns that prevent that cascade. If you are not willing to build those patterns, the boundary will not contain failures. It will just add latency.
Force Five: Business Capability and Domain Boundaries
Conway's Law observes that systems end up mirroring the communication structures of the organisations that build them. An Order team and a Payment team will eventually produce an Order service and a Payment service — not because it is architecturally pure, but because coordinating across a shared codebase between teams with different goals, different stakeholders, and different release cadences becomes more painful over time than managing a network boundary.
This is domain decomposition working as intended. The organisational separation and the service separation reinforce each other. Each team owns their data, controls their deployments, and moves at their own pace.
For this to hold, the domain boundaries need to be real. A domain boundary is a place where the business itself sees a separation — where different people care about different things, where different language is used, where different events drive different workflows. When you find that kind of natural seam, it is a strong signal that a service boundary belongs there too.
The signal is weakest when the separation exists only on a whiteboard. Two teams that share a roadmap, report to the same manager, and coordinate every release are not really separate domains yet — regardless of what the diagram says. In that situation, the better move is to let the organisational separation mature first. Once the teams are genuinely independent, the service boundary will follow naturally.
Decision rule: If a component is owned by a team with genuinely different goals, stakeholders, and change cadence from its neighbours, the Domain Force is present. If the teams are still tightly coupled organisationally, invest in clarifying ownership and aligning team structure before drawing a service boundary.
False Signals That Lead to Premature Service Decomposition
Now that you know what real forces look like, you need to know the signals that pretend to be forces but are not. These false signals trick teams into extracting services prematurely, producing all the operational cost of distribution with none of the benefit.
Complexity
"This module is complex" is not a force. It is a symptom, and it might have many different causes — poor abstractions, missing tests, accumulated technical debt, or doing too many things that belong in separate modules within the same deployment unit.
Extracting a complex module into a service does not reduce complexity. It takes the same complexity and wraps a network boundary around it. Now you have a complex service with all the original complexity, plus network latency, serialisation overhead, and distributed debugging challenges. The complexity did not disappear. It moved behind an API where it is harder to see and harder to change.
If complexity is your only pressure, refactor before you extract.
Messiness
"A messy codebase" is not a force. It is a maintenance problem. And distributing a mess produces a distributed mess, which is strictly worse than a localised one. A messy monolith can be understood by opening the codebase and reading it. A messy set of microservices requires understanding deployment pipelines, network topology, service discovery, and observability infrastructure just to begin figuring out what the code does.
The correct response to a messy codebase is disciplined refactoring, not distribution.
Team Intuition Without a Named Force
Team intuition is valuable data, but it is not a force. Intuition is often responding to real problems — cognitive load, unclear ownership, frustration with coordination. These are legitimate concerns. But they do not automatically justify a service boundary.
When a team says "this should be its own thing," the right follow-up question is: which of the five forces is your intuition responding to? If they can name one — data ownership friction, change frequency differences, scaling pressure — you have something to investigate.
Speculative Scaling
"We might need to scale this later" is not a force. The Load Force requires a real, sustained difference in resource requirements you are experiencing now or have clear evidence you will experience soon. A hypothetical future where traffic grows tenfold is not evidence. A vague feeling that something might become a bottleneck someday is not evidence.
Speculative extraction is expensive. Every service you extract adds operational overhead forever — deployment pipelines, observability, versioning contracts, on-call rotation. Do not pay those costs for a future that may never arrive.
When Not to Split a Microservice (Even If Forces Exist)
Forces are necessary conditions for extraction. They are not sufficient conditions. Real forces can be present — two, three, even four of them — and extraction can still be the wrong decision.
Disqualifier One: Latency Sensitivity Is Extreme
Some components require near-zero-latency access to data: a real-time fraud check that must complete within fifty milliseconds, an inventory lookup on every page load, a session validation sitting in the hot path of every authenticated request.
When the data these components need is collocated in the same process today, extracting the component introduces a network hop. That hop takes time. Serialisation takes time. Connection establishment takes time. Under load, queueing adds worst-case latency that can be orders of magnitude higher than in-process communication.
When the latency budget cannot absorb a network hop, the forces may be real but the trade-off does not clear. Keep the components together and accept the coordination cost as the price of meeting your latency requirements.
Disqualifier Two: Transactional Consistency Requires Coupling
Consider a common scenario: payment processing and inventory reservation change at different rates, different teams own them, different compliance requirements apply. The Change Force is present. The Data Force might be. The Domain Force almost certainly is. Forces suggest extraction.
But both operations must succeed or fail together for a checkout to be valid. If payment succeeds and inventory reservation fails, the customer is charged for an item that cannot be shipped. If inventory is reserved and payment fails, stock is held for an order that will never complete. The business requires atomicity across both operations.
Separating them introduces distributed transaction complexity — sagas, compensating transactions, idempotency keys, careful failure handling. This complexity is often worse than the deployment coordination cost you were trying to avoid. Keep components together until you have designed a working consistency model. Only then should you consider extraction.
Disqualifier Three: Load Is Bursty, Not Sustained
A component needs fifty times its normal capacity for two hours on Black Friday. The rest of the year it runs at modest utilisation. This is a spike, not a sustained difference. The Load Force is not actually present, even though the scaling differential is dramatic.
Operating a separate service costs you something every day — deployment pipelines, observability infrastructure, alerting configurations, on-call rotation. If you only need the extra capacity for two hours a year, it is almost certainly cheaper to over-provision the component within the combined service for those two hours than to operate a separate service for twelve months.
Save extraction for sustained differences, not spikes.
Disqualifier Four: The Owning Team Does Not Yet Exist
Conway's Law works in both directions. Organisation structure shapes system structure, but system structure also shapes organisation structure. Draw a service boundary before the team that will own it exists and you have a service without a clear owner. Ownerless services degrade faster than modules in a shared codebase. Their APIs drift. Their documentation grows stale. Their on-call rotation falls to whoever is available when something breaks.
The correct sequence is team first, then service. Let the team form around a business capability. Let them take ownership of a module inside the combined service or monolith. Let them establish their change cadence, their coding standards, their deployment preferences. Then, when the team is stable and the forces are pressing, extract the service.
If the team does not yet exist, do not extract. Wait.
A Concrete Example: Should Payments Be a Microservice?
Let us walk through a real decision to show how the framework works together. A team of eight engineers is building an e-commerce checkout system. They have been running a modular monolith for three months. The Payments module handles card tokenisation, payment provider calls, refund logic, and transaction records. The question on the table: should Payments become its own service?
Step one: the observability gate. Do they have distributed tracing? Yes. Structured logs with correlation IDs? Yes. Built in month one. The gate clears.
Step two: apply the five forces.
Data Force: The Payments module owns transaction records — financial data with its own compliance requirements. Schema changes are already causing cross-team coordination pain. Multiple writers, friction already visible. Force present. Strong.
Change Force: Payments integrates with external payment providers whose APIs change on their own schedule. In the past two months, Payments deployed four times while Order deployed once. Force present.
Load Force: Payments handles roughly the same request volume as Order. No meaningful difference in resource profile. Force absent.
Reliability Force: A payments failure today degrades the entire checkout flow. After extraction, would the boundary actually contain failures? The team commits to implementing circuit breakers and proper timeouts. The boundary can be a real failure boundary. Force present, conditional on delivery.
Domain Force: The payments engineer owns a sub-domain with different stakeholders — finance, compliance — and a different release cadence. A team is forming around financial services. Force present.
Four forces present. One absent.
Step three: the false signal radar. Is this extraction driven by complexity, messiness, or speculative scaling? No to all. The radar is clear.
Step four: check the disqualifiers. Does extraction violate a tight latency budget? No — the synchronous call from Order to Payments is acceptable within budget. Does it require a distributed transaction? Order needs a payment result before confirming, but that is a call, not a transaction spanning two databases. Is the load pattern bursty rather than sustained? The Load Force was absent anyway. Does the owning team not yet exist? The team is forming with clear ownership. No disqualifiers apply.
The decision: extract Payments. Four forces present, clean data boundary, observability in place, no distributed transaction required. The decision is justified.
Closing Thought
This framework will not tell you exactly where every boundary belongs. No framework can. But it will save you from the most common and most expensive mistakes — extracting when you should refactor, extracting when you should wait, extracting when you should keep things together.
The services that last are not the ones an architect drew on a whiteboard. They are the ones the system demanded. Your job is to listen for the forces, build observability first, ignore the false signals, respect the disqualifiers, and extract only when the pressure becomes impossible to ignore.
About N Sharma
Lead Architect at StackAndSystemN Sharma is a technologist with over 28 years of experience in software engineering, system architecture, and technology consulting. He holds a Bachelor’s degree in Engineering, a DBF, and an MBA. His work focuses on research-driven technology education—explaining software architecture, system design, and development practices through structured tutorials designed to help engineers build reliable, scalable systems.
Disclaimer
This article is for educational purposes only. Assistance from AI-powered generative tools was taken to format and improve language flow. While we strive for accuracy, this content may contain errors or omissions and should be independently verified.