Learning Paths
Last Updated: April 29, 2026 at 11:00
Synchronous vs Asynchronous Communication in Microservices: Trade-offs, Failure Modes, and When to Use Each
A practical guide to choosing how your services talk to each other based on consistency needs, load patterns, and operational reality
Synchronous communication gives you immediate responses but couples your services in time. Asynchronous communication makes your system more resilient but introduces new complexity around ordering, idempotency, and debugging. The real question is not which is "better" but which failure modes you can tolerate. This guide walks you through a weighted decision framework so you can design microservices that actually work in production.
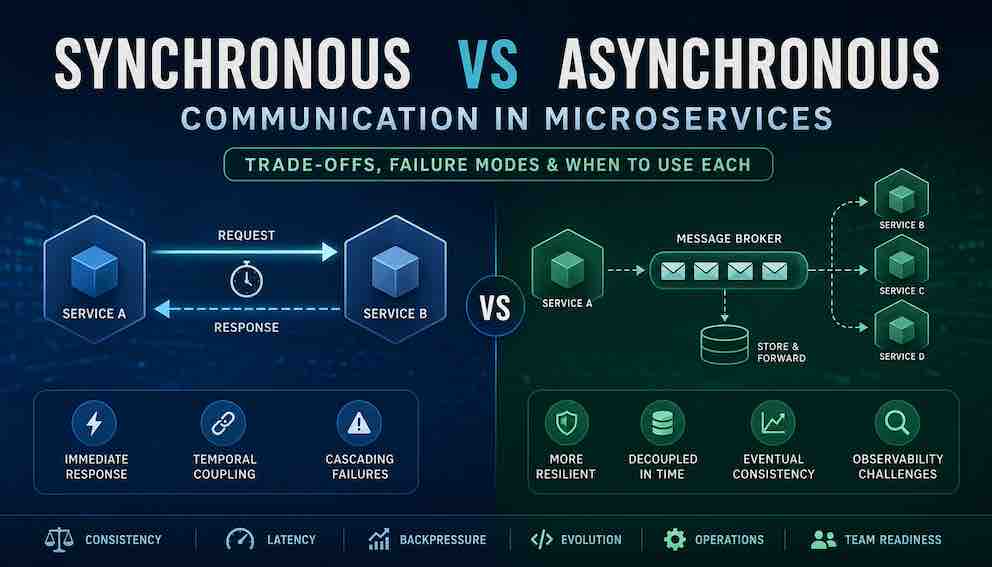
Why This Choice Shapes Everything
You're designing a microservices architecture. Service A needs data from Service B. Service C needs to notify Service D when something happens. Two familiar paths emerge: synchronous (HTTP/gRPC) or asynchronous (Kafka/RabbitMQ).
Most advice stops at "sync is simpler" or "async is more scalable" — but that doesn't help you decide. It just leaves you stuck.
Here's a better way to think about it: Synchronous communication optimises for immediacy and simplicity. Asynchronous communication optimises for resilience and independence.
Neither is right or wrong. Each makes different things easy and different things hard. The real question isn't "which is better?" — it's "which strengths matter most for this specific interaction?"
Sync gives you fast answers and straightforward debugging. Your call either works or fails immediately, and you know exactly why.
Async gives you fault tolerance and decoupled services. Your system keeps working even when individual pieces go down or need deployment.
This guide walks you through exactly when to use each — and introduces the powerful hybrid patterns (async request-reply, CQRS-lite) that sit between them. You'll leave with a weighted decision framework that turns a confusing trade-off into a confident architectural choice.
A Mental Model: Chain, Flow, and Something in Between
Before diving into trade-offs, it helps to visualise the fundamental difference in how these patterns think about work.
Synchronous communication forms a chain of responsibility.
Each link depends on the next. The chain is alive together. If any link breaks, the whole chain breaks immediately. Debugging means following the chain from start to end.
Asynchronous fire-and-forget communication forms an event propagation graph.
No link waits for another. Events flow through time independently. Debugging means reconstructing a timeline across services.
But there is a third shape: async request-reply. Service A publishes a request to a queue with a reply-to address, then waits (with a timeout) for Service B to send a response to a private reply queue. The user still waits for an answer — the interaction is logically synchronous — but the transport is asynchronous. This matters for reasons we will cover shortly.
Keep all three images in mind as we work through the trade-offs. The choice is rarely binary.
Failure Modes and Timing
How synchronous communication fails. Imagine Service A calls B, which calls C. C becomes slow. A and B wait. Threads pile up. If C fails completely, A and B fail too. One slow service can take down everything upstream. This is a cascading failure, and retries make it worse — each service retries independently, multiplying load on the already-struggling downstream service.
Synchronous failures are immediate and visible. Errors surface in real time. Monitoring alerts fire. You know something is wrong right now.
How asynchronous communication fails. Imagine Service A publishes an event. Service B consumes it. B becomes slow. Messages pile up in the queue, but A continues happily and the user sees no error. Hours later, the queue holds millions of messages, the broker runs out of disk, and everything stops. Or a single malformed message crashes the consumer repeatedly — a "poison message" — and the queue backs up entirely behind it.
Asynchronous failures are delayed and invisible. The problem grows silently. By the time you notice, recovery is a major operation.
The key insight: synchronous systems fail in real time, asynchronous systems fail in time-shifted aggregates. Neither is inherently more dangerous. They are dangerous in different time frames, and your monitoring strategy needs to reflect that entirely different shape of failure.
Consistency and Correctness
Here's the core tension: synchronous gives you immediate Consistency. Asynchronous gives you correctness over time. Choose based on what your users actually need.
What synchronous gives you
Service A calls B, B updates its database and returns success, A updates its database. Both changes happen within the same request. You know immediately if it worked or failed.
But watch for lock contention. If B holds a database lock while waiting for A (which might call other services), that lock stays open much longer than intended. What looks like a network timeout is often a transaction design problem. Async naturally avoids this—B commits its transaction before doing any downstream work.
Synchronous optimises for: Correctness at a single moment. The request either fully succeeds or fully fails, and you know which right away.
What asynchronous gives you
Service A updates its database and publishes an event. Service B processes it later. For seconds or minutes, the system is inconsistent—a user might see stale data.
But here's the upside: Even if services fail or networks partition, you can replay events and converge on the correct state. This is why many systems use async events despite the complexity—correctness over time matters more than an immediate response.
Asynchronous optimises for: Correctness across a timeline. The system may be temporarily wrong, but it can become permanently right.
The question to ask yourself
Do you need correctness at a single moment? Go synchronous.
Do you need correctness across a timeline? Go asynchronous.
Latency and User Experience
Here's the simple truth: synchronous makes users wait. Asynchronous makes users wonder.
Synchronous: The user waits for everything
When Service A calls B, and B calls C, the user waits for all of it. A 50ms call plus another 50ms call equals 100ms of waiting.
The hidden problem: In deep chains (4-5 services deep), the slowest 1% of requests get much slower—often 300-600ms instead of the 200ms you'd expect. This is why large systems avoid deep synchronous chains.
Choose sync when: The user needs an immediate answer AND your call chain is shallow (2-3 services max).
Asynchronous fire-and-forget: The user doesn't wait
The request comes in. You say "got it, we'll process it." User sees a fast response. The actual work happens later.
The trade-off: The user doesn't know if it worked. You need a follow-up—email, push notification, or a "check status" page. This changes how your product feels.
Choose async fire-and-forget when: You can honestly tell the user "we'll let you know" (email sending, report generation, notifications).
Async request-reply: The best of both (with a cost)
What it is: Service A publishes a request message to a queue, but includes a "reply-to" address (a private queue just for this response). Service A then waits—with a timeout—for Service B to process the request and send a response back through that private queue. The user still waits for an answer, but the transport underneath is asynchronous.
Think of it like: Submitting a form and waiting at your desk. A clerk takes your form to the back office. You don't follow them—you wait. They return with your answer when it's ready. The waiting feels synchronous, but the work happened asynchronously.
Why use this instead of plain HTTP? Because the queue buffers the request. If Service B restarts or briefly scales down, your call doesn't fail—the message sits safely in the queue until Service B is ready. You also get natural backpressure: if the queue is too deep, you can reject new requests at the edge instead of letting threads pile up.
The trade-offs: You add a small amount of extra latency (the round-trip through the queue broker) and more moving parts to operate compared to a direct HTTP call.
When to choose it: The user is waiting for an answer, but you need services to deploy independently OR you want queue-based backpressure instead of thread pool exhaustion.
Good examples: Address validation, shipping cost calculations, fraud scoring. These are user-facing (the user needs an answer) but not ultra-latency-sensitive (50ms vs 150ms doesn't ruin the experience).
The simple rule of thumb
- Synchronous → User waits for an answer. Keep chains shallow.
- Async fire-and-forget → User gets "we'll let you know." Add a notification path.
- Async request-reply → User waits, but a queue buffers underneath. Great for user-facing work that needs decoupling.
Coupling: What You Actually Decouple
Everyone says asynchronous patterns decouple services. That is true, but the precision matters.
Synchronous communication creates temporal coupling. Both services must be running at the same moment. If Service B is down for a deployment, Service A's calls fail. You cannot deploy B without coordinating with A.
Asynchronous communication removes temporal coupling. Service A publishes an event without caring whether B is up. The broker stores the message until B returns. You can deploy services independently.
But here is what asynchronous communication does not remove: structural coupling. Service A and B must agree on the message format. Changing a field name breaks consumers in both communication styles. The difference is visibility. In synchronous calls, a breaking change fails immediately and loudly. In asynchronous messaging, a breaking change might silently route messages to a dead-letter queue for days before anyone notices.
Asynchronous communication transforms coupling from temporal to structural, and makes structural mismatches significantly harder to detect. If your team adopts async, you need a schema registry and a versioning strategy for your message contracts — otherwise you have traded one coupling problem for a harder one.
Backpressure and Load Behaviour
First, what is backpressure? It's a system's way of saying "I'm full, stop sending." Think of a restaurant kitchen: when orders pile up, the waiter stops taking new orders until the kitchen catches up. Backpressure pushes the problem upstream so the weakest link doesn't get crushed.
Now let's see how sync and async handle this differently.
Synchronous: Backpressure propagates naturally
Service B can handle 100 requests per second. Service A sends 200. Service B's thread pool fills up. New requests to B start waiting or timing out. Service A's calls to B begin failing. Service A sees those failures and—if designed well—stops sending new requests to B.
How backpressure works in sync: The slowdown travels upstream automatically. Each service feels the pain of the service below it.
The result: The system self-limits. You might serve 100 requests per second instead of 200, but you won't try to serve 200 and collapse.
The trade-off: Backpressure reaches the user. Some requests fail. They see an error.
The key insight: In sync, backpressure is automatic but user-visible.
Asynchronous: Backpressure is optional (and often missing)
Service B can handle 100 requests per second. Service A sends 200. The queue between them grows. Service A's call completes instantly—it just wrote to the queue. Service A has no idea B is struggling.
How backpressure works in async: It doesn't exist by default. The queue acts as a buffer, absorbing the load difference. Service A never slows down.
The result: The system accepts everything. The queue grows indefinitely if the imbalance persists.
The trade-off: You must build backpressure yourself. Monitor queue depth. Reject requests at the edge when the queue exceeds a threshold. Otherwise, the queue grows until the broker fails.
The key insight: In async, backpressure is optional but user-invisible (if you build it, you reject requests before they enter the queue; if you don't, the queue just grows).
Which handles load better?
It depends on what "better" means to you:
- Protecting the system from overload? Both can work, but sync does it automatically. Async requires you to build it.
- Never showing users an error? Async wins, but only if you accept unbounded queue growth OR massively over-provision.
- Predictable recovery after a spike? Sync wins. Fail fast, retry later. Async recovery time equals queue backlog depth divided by processing rate.
- Absorbing a spike without dropping anything? Async wins, but you need enough disk and catch-up time.
- Knowing there's a problem immediately? Sync wins. Failures are visible right away. Async problems hide in growing queues.
The architectural reality: Sync gives you automatic backpressure at the cost of user-visible failures. Async gives you no backpressure by default—you must add it deliberately—but can absorb spikes without dropping work if you're willing to let the queue grow.
Choose sync when: You want the system to protect itself automatically, and you accept that users may see errors during load spikes.
Choose async when: You cannot drop work (every request matters), you have the monitoring to watch queue depth, and you've built explicit backpressure (reject at the edge) or you accept delayed processing as a trade-off.
The key question: Do you want backpressure to be automatic (sync) or deliberately engineered (async)? Neither is wrong. But if you choose async and forget to engineer backpressure, you don't have a load-resilient system.
Observability and Debugging
Debugging: Sync follows a simple request chain. You ask "why did this fail?" and tools like Jaeger show you. Async asks "where did this event go missing?"—producer, broker, or consumer?—which requires event timeline tooling, not just request tracing. (If you want to understand observability in depth, see the guide.)
Operations: Sync needs load balancers, timeouts, and circuit breakers. Async needs all of that plus a message broker, dead-letter queues, replay mechanisms, and queue-depth alerting. Plan async tooling before you commit. If you don't have it, you won't see problems until they're critical.
Dead-Letter Queues: The Operational Reality
A dead-letter queue catches messages that repeatedly fail. Without one, a single bad message blocks your entire queue. But having a DLQ is just the start. Someone must monitor its depth, decide replay strategies, and handle poison messages. Some systems even need a DLQ for their DLQ. Sync systems don't have this problem—a failed call just fails, you log it, you fix it. Before going async, ask: does your team have the culture and tooling to run DLQs properly?
Idempotency, Ordering, and Exactly-Once Delivery
If you choose asynchronous microservices communication, these three concepts are non-negotiable. They are not advanced features — they are the baseline.
Idempotency means processing the same message twice produces the same result as processing it once. In asynchronous systems, messages can and will be delivered more than once. A broker may redeliver after a consumer timeout. A consumer may process a message, crash before acknowledging, and then process it again on restart. Setting an order status to "shipped" twice is fine. Charging a payment card twice is a serious incident. Design every consumer to be idempotent. Test for duplicate delivery explicitly.
Ordering is not guaranteed by most brokers in all configurations. Kafka guarantees ordering within a partition, but messages across partitions interleave. RabbitMQ with multiple consumers can deliver messages out of sequence. If your workflow requires "OrderCreated" to be processed before "OrderPaid," you must design for that constraint.
Exactly-once delivery is a myth in distributed systems. What brokers market as "exactly-once" is actually at-least-once delivery combined with idempotent consumers. Even Kafka's transactional exactly-once guarantee applies within a single Kafka cluster — it does not extend across external systems like databases or third-party APIs. Design for duplicates. Assume duplicates will occur. Test for them in staging.
If your team is not ready to implement these three properties on critical data paths, do not use asynchronous communication there.
The Outbox Pattern: Bridging Sync and Async Safely
One of the most common failure points in asynchronous microservices is the gap between writing to your database and publishing an event. If Service A writes to its database and then crashes before publishing the event, the database is updated but the event is lost. Downstream services never know the change happened.
The Outbox Pattern solves this. Instead of publishing directly to the broker, Service A writes the event to an "outbox" table in the same database transaction as its main data change. A separate relay process reads from that outbox table and publishes to the message broker, then marks messages as sent. Because the write to the outbox is part of the same transaction, you either get both the data change and the queued event, or neither. You eliminate the gap.
This pattern is essential for any asynchronous workflow where losing an event would cause data inconsistency. If you are building async microservices and you have not considered the Outbox Pattern, add it to your design review checklist now.
CQRS-Lite: Sync Reads, Async Writes
One of the most widely used hybrid patterns in production microservices goes by several names. The formal version is Command Query Responsibility Segregation (CQRS). In practice, most teams implement a lighter version that delivers most of the benefit without the full architectural commitment.
What it is: A hybrid pattern where writes (creating/updating data) happen asynchronously, but reads (looking up data) stay synchronous.
The simple version: Writes go async. Reads stay sync.
How it works in practice:
A user places an order. The Order Service saves it to its database and publishes an OrderCreated event. Other services (inventory, fulfilment, notifications) consume that event and update their own data stores in the background.
When the user checks their order status, the query goes directly—synchronously—to a read service that already has the answer ready.
What you get:
- Writes are decoupled and resilient. One slow service doesn't block the order.
- Reads are fast and simple. No waiting for downstream calls.
The trade-off (read-after-write inconsistency):
A user places an order and immediately refreshes the page. For a few milliseconds or seconds, the order might not show up yet. The read side hasn't caught up.
Is this acceptable? For most systems, yes. Users understand slight delays. If not, you can work around it (client-side cache or routing the user's own reads back to the write side briefly).
Bottom line: If your writes need resilience and your reads need speed, design CQRS-lite from the start.
Two Real Incident Stories
Two stories that show the mirror-image nature of these failure modes.
The synchronous cascade. A team had a chain: API Gateway → Order Service → Payment Service → Inventory Service. During a flash sale, Payment Service degraded from 50ms to 2 seconds. Order Service's thread pool filled waiting for payment responses. Soon Order Service could not accept new requests at all. The API Gateway timed out. Users saw errors. The whole system failed in under thirty seconds.
The outcome? They knew instantly. Monitoring fired. They traced the problem to Payment Service in two minutes, applied rate limiting, and recovered in ten minutes. The failure was sharp and painful, but contained and recoverable quickly.
The asynchronous flood. A different team built an order system with asynchronous messaging. Order Service published events, Payment Service consumed them. During a similar sale, Payment Service degraded. The queue grew — but Order Service kept accepting orders. Users saw success responses.
The queue grew to 500,000 messages. Payment Service processed 10 per second. The backlog would take fourteen hours to clear. Nobody knew for two hours because queue-depth monitoring was not configured. By the time the team responded, customers had been waiting hours for payment confirmations that never arrived. Support was overwhelmed. Recovery required pausing new orders and replaying the entire queue.
The synchronous system failed fast and visibly. The asynchronous system failed slow and invisibly. Both failed. The question is which failure mode your team can detect and recover from.
A Weighted Decision Framework
Rather than a rigid checklist, weight the factors that dominate your specific situation.
Step one: Identify your dominant constraint.
If user-facing latency is your dominant constraint, lean synchronous — but keep your call chains shallow to avoid tail latency compounding [the rare slow requests get MUCH slower as chain length increases, e.g., three 100ms services can produce 600ms+ for the slowest 1% of users].
If resilience under partial failure is your dominant constraint, lean asynchronous. You need the system to keep working even when individual services are down.
If operational simplicity is your dominant constraint, lean synchronous. Asynchronous adds brokers, dead-letter queues, replay mechanisms, queue-depth monitoring, and DLQ operational processes — all of which require sustained investment to run well.
If long-term correctness and auditability are your dominant constraints, lean asynchronous. Event sourcing and replay give you capabilities that synchronous systems simply cannot match.
If you need user-facing speed on reads but write resilience on commands, consider CQRS-lite from the start rather than bolting it on later.
Step two: Evaluate your secondary constraints.
Can you tolerate eventual consistency? If not, synchronous is close to mandatory for those paths. Does your team have experience operating a message broker? If not, the async learning curve is steep and should be factored into your timeline. Do you need message replay for compliance, debugging, or recovery? Asynchronous systems give you this naturally. Do you have the operational culture to run DLQs proactively, not reactively?
Step three: Make the call.
User waiting + immediate consistency + simple operations → synchronous.
System resilience + load absorption + long-term auditability → asynchronous.
User waiting but temporal decoupling matters → async request-reply.
Write resilience + read speed + acceptable eventual consistency on reads → CQRS-lite.
Uncertainty → start synchronous and introduce async for specific, proven pain points.
Common Anti-Patterns to Avoid
Synchronous calls for batch processing. Calling a downstream service synchronously for ten thousand items in a loop destroys throughput and ties up thread pools. Use async batching or parallelised workers.
Asynchronous acceptance without user feedback. You accept an order, publish a message, return "accepted." The user never learns whether it succeeded. If you use async for user-initiated actions, you must close the loop — via email, push notification, or a status endpoint. Silence is not an acceptable UX.
Consumers without idempotency. If your message consumer isn't idempotent, a redelivered message can charge a user twice. This isn't a theoretical edge case—it happens regularly in production. Build idempotency from day one.
Synchronous calls without timeouts. A downstream service hangs indefinitely. Your threads hang with it. The service starves. Always configure timeouts, and pair them with circuit breakers so repeated failures stop propagating upstream.
Asynchronous queues without dead-letter queues. A poison message crashes the consumer repeatedly. Nothing else in the queue processes. Dead-letter queues catch messages that repeatedly fail, let you inspect them, and keep the main queue flowing. But having a DLQ is not enough — you need alerting on its depth and a runbook for replaying it.
Changing message schemas without versioning. Renaming a field breaks consumers silently. Use a schema registry, design for backward compatibility, and version your message contracts before you have more than one consumer.
Deep synchronous chains without tail latency budgets. Five services, each with a typical latency of 80ms, might suggest users wait 400ms. But the slowest 1% of requests at each service can align, turning 80ms into 200ms at one hop, 300ms at another. The user ends up waiting 600ms, 800ms, or more. Set an end-to-end budget and measure actual latency. Do not assume latencies simply add.
When to Use Synchronous Communication
Use synchronous microservices communication when:
- The user is waiting for an immediate answer (login, search, purchase confirmation)
- You need immediate consistency across services
- The workflow is short with a shallow call chain
- Your team is new to microservices and needs operational simplicity
- You need failures to be fast, visible, and easy to trace
- You cannot currently operate and monitor a message broker
When to Use Asynchronous Communication
Use asynchronous fire-and-forget communication when:
- The user does not need an immediate answer (email sending, report generation, notifications)
- You need temporal decoupling so services can deploy independently
- You expect load spikes and can monitor queue depth proactively
- You need message replay for auditability, debugging, or compliance
- You are willing to invest in DLQ operations, idempotency, and ordering design
- You are implementing the Outbox Pattern or Saga for distributed write workflows
When to Use Async Request-Reply
Use async request-reply when:
- The user is waiting for an answer but temporal decoupling matters (the downstream service needs to scale or restart independently)
- The operation is user-facing but not latency-critical — address validation, shipping calculations, fraud scoring
- You want queue-based backpressure instead of thread pool exhaustion
- You can accept the added latency of a broker round-trip
When to Use a Hybrid Approach
Use synchronous and asynchronous communication together when:
- You need synchronous on the critical user-facing path and asynchronous for side effects — this is the most common production pattern
- You are implementing CQRS-lite: async writes via events, sync reads against materialised views
- You are using the Outbox Pattern to safely bridge a database write and an async event
- You are implementing Sagas for distributed transactions that span multiple services
The Architect's Rule of Thumb
If the user is waiting, use synchronous — or async request-reply if temporal decoupling matters. If the system is working in the background, use asynchronous.
Users wait for a login, a purchase result, a search response. Those paths should be synchronous. The system works in the background to send a confirmation email, update a search index, generate a report. Those paths should be asynchronous.
And for the large class of systems where writes must be resilient but reads must be fast, reach for CQRS-lite before you reach for a fully event-driven architecture.
This rule covers the majority of decisions you will face. For the remainder, you now have the framework to make a deliberate and defensible choice.
Summary
The best communication pattern for microservices is not the simpler one or the more scalable one. It is the one whose failure modes you understand and can tolerate.
Synchronous communication fails fast and visibly. You see problems immediately. But it couples your services in time, propagates failures up the call chain, and compounds tail latencies in deep call graphs.
Asynchronous communication fails slowly and invisibly. Problems hide in growing queues and dead-letter backlogs that require active operational management. But it decouples your services, absorbs load spikes, and provides replay and auditability that synchronous systems cannot match.
Async request-reply gives you a logically synchronous user experience with the temporal decoupling and backpressure characteristics of a queue — a middle mode worth keeping in your toolkit.
CQRS-lite — async writes, sync reads — is the pattern most mature microservices systems converge on for their core domain operations. If your system is growing in that direction, design for it deliberately rather than discovering it by accident.
Do not ask which is better. Ask: is the user waiting for this response? Can I tolerate eventual consistency on this path? Does my team have the operational culture to run dead-letter queues well? Am I ready to implement idempotency and handle ordering? Will my tail latency budget survive a deep synchronous chain?
Start synchronous. Add asynchronous where it solves a real, demonstrated problem. Use CQRS-lite when your write and read scaling requirements diverge. Use async request-reply when you need temporal decoupling without giving up a synchronous user experience.
About N Sharma
Lead Architect at StackAndSystemN Sharma is a technologist with over 28 years of experience in software engineering, system architecture, and technology consulting. He holds a Bachelor’s degree in Engineering, a DBF, and an MBA. His work focuses on research-driven technology education—explaining software architecture, system design, and development practices through structured tutorials designed to help engineers build reliable, scalable systems.
Disclaimer
This article is for educational purposes only. Assistance from AI-powered generative tools was taken to format and improve language flow. While we strive for accuracy, this content may contain errors or omissions and should be independently verified.