Learning Paths
Last Updated: April 28, 2026 at 08:00
REST vs GraphQL vs gRPC: Trade-offs, Performance, and When to Use Each
A practical guide to choosing your API architecture based on real constraints, not hype
Choosing between REST, GraphQL, and gRPC means understanding which trade-offs your system can live with. REST is simple and cacheable but can be chatty. GraphQL offers flexibility but shifts complexity to the server. gRPC delivers speed and streaming for internal services but struggles in browsers. This guide walks you through eight decision axes so you can leave with a confident choice.
The Real Problem: Why This Choice Is Hard
You are designing an API. You have heard about REST, GraphQL, and gRPC. Each one has passionate advocates. Each one powers successful systems. And yet, when you sit down to make a choice for your own project, the answer is never obvious.
That is not because you are missing something. It is because the choice is genuinely hard. The right answer depends on who is calling your API, how they need to use it, what your performance constraints are, and what your team is ready to operate.
So let us walk through that decision together. The goal here is not to declare one technology the winner. The goal is to help you look at your specific system and know exactly which tool fits best, whether you are building a simple blog, a mobile banking app, or a set of internal microservices.
Here is the core idea to hold onto for the rest of this article: REST, GraphQL, and gRPC are not competing for the same job. They are different tools — like a hammer, a screwdriver, and a drill. You would not ask which tool is "best." You would ask what you are trying to build. Let us figure that out together.
A Quick Mental Model
Before we dive into the decision axes, let us build a clear mental picture of what each technology actually is. Even if you already know one or two of them, reading through all three will help you see how they differ.
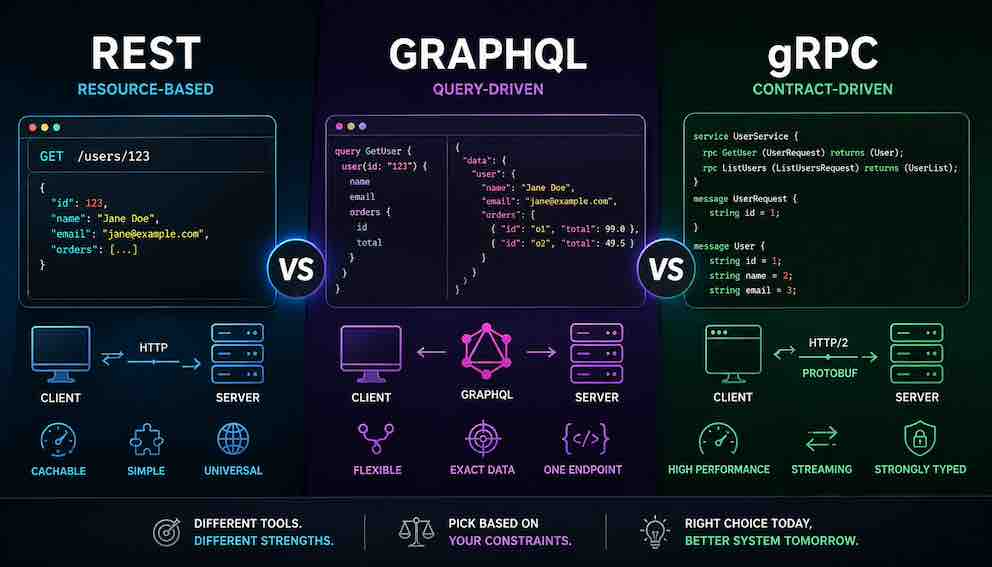
REST is resource-based.
Think of REST like a restaurant menu. The menu lists specific dishes: a cheeseburger, a side of fries, a chocolate milkshake. You order from what is on the menu. You cannot ask for "half a cheeseburger with extra pickles and only five fries." You get what the menu offers.
In REST, you think in terms of nouns: users, orders, products. Each has its own web address, like /users/123 or /orders/456. You interact with these resources using standard HTTP verbs. GET fetches. POST creates. PUT updates. DELETE removes.
When you ask for /users/123, the server sends back whatever it has defined for a user. You do not get to pick which fields. You get the whole user object, or whatever the server decides to send. This predictability is the strength. Every developer understands it. Every tool supports it. It works great for public APIs.
GraphQL is query-driven.
Now imagine a restaurant that offers a detailed menu with every possible ingredient and preparation method listed. The menu tells you exactly what is available: burger patties, three types of lettuce, two kinds of cheese, a specific list of toppings. You can choose any combination of these available items, but you cannot order something that is not on the menu. You want avocado? The menu does not list it. You cannot order it.
That is GraphQL. The server exposes a schema that defines exactly what fields and nested relationships are available. A user might have a name, an email, a join date, and a connection to their recent orders. An order might have an ID, a total, and a connection to the products inside it.
The client writes a query that asks for specific fields from within that schema. It can request just the user's name and email, leaving out the join date. It can nest deeper and ask for a user, their recent orders, and within each order, just the product names and prices. But it can only ask for what the schema defines. The schema is the contract. If the schema does not connect users to orders, the client cannot ask for that relationship.
This solves two problems that REST often has. Over-fetching is when the server sends you twenty fields but you only needed two. Under-fetching is when the server sends you a user but not their orders, so you have to make a second request. GraphQL eliminates both by letting the client ask for exactly the fields it needs from the schema, in one round trip.
The trade-off is complexity. The server team must design and maintain a thoughtful schema. The schema must anticipate what clients will need. Caching is harder because every query is different, even if they ask for overlapping data. GraphQL gives you flexibility, but only within the boundaries the server defines.
gRPC is contract-driven.
Now imagine two restaurants that need to work together closely. They serve thousands of customers together every minute. They cannot afford misunderstandings. So they sit down ahead of time and sign a detailed contract.
The contract says: "When you send us an order, it must contain a customer ID as a number, a list of item IDs as an array of numbers, and a special instructions field as a string. We will respond with an order ID as a number and an estimated wait time as a number."
Once the contract is signed, both restaurants generate code from that contract. They now have pre-built functions for sending and receiving orders. The messages are sent in a compact binary format, not human-readable text. This is very fast.
This is gRPC. You define a strict contract using Protocol Buffers (Protobuf). You run a tool that generates client and server code. The communication is typed, fast, and efficient.
gRPC also handles streaming naturally. The client can stream multiple messages. The server can stream back. Or both can stream at the same time.
The catch is that gRPC was designed for servers talking to other servers inside your own infrastructure. Using it directly from a web browser is difficult because browsers do not fully support the underlying HTTP/2 features that gRPC requires. For internal services, gRPC is fantastic. For public browser-facing APIs, it is usually the wrong tool.
Keep this picture in mind.
REST is the fixed menu. You choose from whole dishes. GraphQL is the build-your-own menu with a defined list of ingredients and allowed combinations. You can combine them flexibly, but only within what the menu author has made available. gRPC is the pre-signed contract between trusted partners. Very fast, very precise, but not for public use.
These three are not competing for the same job. They are different tools for different situations. The most important decision you will make is matching the right tool to the right job. Let us figure out how to do that.
Eight Axes for Choosing the Right API
Axis 1: Who Is Calling Your API?
This is the single most practical question you can ask, and it will often eliminate one option immediately.
If your API will be called directly from a web browser or a mobile app, gRPC is almost always the wrong choice. Browsers do not natively support gRPC. You would need a special proxy or translation layer, which adds complexity you almost certainly do not need at the start.
For client-facing APIs, your real decision is between REST and GraphQL. REST is simpler and works everywhere. GraphQL gives you more control over data shape at the cost of extra thinking — for both the team building the API and the team consuming it.
If your API is only for services communicating inside your own data centre or cloud account — for example, an order service calling a payment service, which then calls a shipping service — gRPC becomes very attractive. It is fast, strongly typed, and handles streaming cleanly. REST and GraphQL are still perfectly valid for internal services, but gRPC often wins on raw performance once traffic is significant.
A pragmatic note on technology diversity.
You might find yourself in a situation where you have some APIs that face external clients and other APIs that are internal only. The technically optimal choice might be REST or GraphQL for the external ones and gRPC for the internal ones. That is a valid architecture.
However, ask yourself whether the performance gains from gRPC are truly necessary for your internal traffic. If raw performance is not a key requirement, there is real value in sticking with a single technology across your entire system. Every additional technology adds cognitive load for your team, complicates onboarding, multiplies your tooling needs, and creates more surface area for bugs. There is a cost to diversity that is rarely captured in benchmark comparisons.
Many successful systems run entirely on REST, even internally, simply because the consistency and simplicity outweigh the performance difference. Others introduce gRPC only when they have measured a clear need. Both approaches are valid. Just make the choice deliberately, not by default.
Start here: is the caller a browser or mobile app, or is it another backend service? Your answer to that question will point you in a direction. Then ask yourself whether the marginal benefit of adding a second technology is worth the operational tax.
Axis 2: Data Flexibility Needs
Imagine a user profile that contains a name, an email address, a list of recent orders, shipping addresses, payment methods, and preferences.
In REST, you might have one endpoint that returns everything. A mobile app that only needs the name and email still receives the entire object. That is over-fetching — wasted bandwidth and wasted battery life. Conversely, if a different screen needs product details nested inside those orders, you might have to make multiple sequential requests. That is under-fetching.
In GraphQL, the client writes a query asking for exactly what it needs. The mobile app asks for name and email. The dashboard asks for everything. The analytics tool asks only for order history. One endpoint serves all of them, and nobody gets data they did not ask for.
This is GraphQL's core superpower, and it genuinely shines when you have multiple clients with different data requirements — particularly mobile and web clients that share a backend.
But there is a catch. If your API is simple — a handful of endpoints that map neatly to your database — REST is perfectly adequate.
Ask yourself: do I have multiple clients with meaningfully different data needs? If the answer is yes, GraphQL deserves a serious look. If the answer is no, REST is almost certainly simpler.
Axis 3: Performance Model
Everyone says gRPC is fast, and that is true. But you need to understand why it is fast, and whether that specific kind of speed actually matters to your use case.
It helps to separate two different concerns: network round trips and server-side computation cost.
REST often requires multiple round trips. You fetch a user, then their orders, then the products inside those orders. Each trip adds latency. However, REST can cache aggressively at the HTTP layer, meaning cached responses never touch your servers at all.
GraphQL reduces round trips dramatically. One query can fetch a user, their orders, and the products within those orders in a single request. But there is a hidden cost. That one query may trigger dozens of database calls on the server unless you implement batching carefully. The client perceives a single fast response, but your server may be doing substantially more work than a simple REST endpoint would.
gRPC uses Protobuf, a binary serialisation format that is smaller than JSON and faster to parse. Combined with HTTP/2 multiplexing — which allows multiple requests and responses to flow concurrently over a single connection — it achieves very high throughput for internal service-to-service traffic. The trade-off is that you lose HTTP caching entirely.
So here is how you choose. If your biggest problem is chatty clients making too many round trips, GraphQL helps. If your biggest problem is server CPU struggling to parse JSON, gRPC helps. If your biggest problem is serving the same data to millions of users and you need a CDN, REST is your only real option. The answer depends on where your actual pain is.
Axis 4: Real-Time and Streaming
Some applications need the server to push data to clients as it happens — a live chat application, a sports scoreboard, a stock ticker, or a system monitoring dashboard.
REST is not designed for this. You can simulate it with polling, where the client asks for updates every few seconds, but polling is wasteful and slow to respond. You can use WebSockets, but that is a separate protocol requiring its own infrastructure.
GraphQL offers subscriptions, which allow a client to receive updates over a persistent connection whenever a subscribed event occurs. Subscriptions work, but they add meaningful complexity. Managing persistent connections, handling reconnections, and ensuring subscription support in your chosen GraphQL client library all require care.
gRPC has streaming built directly into the protocol. You can stream from the client, from the server, or bidirectionally — where both sides send and receive messages freely. This is one of gRPC's strongest features. If you need real-time, high-frequency communication between backend services, gRPC makes that straightforward.
A practical rule: for bidirectional streaming deep inside your backend, gRPC is the clear winner. For simpler one-way real-time updates to a web or mobile client, GraphQL subscriptions work — but a dedicated WebSocket or server-sent events approach is often more straightforward.
Axis 5: Error Handling Model
This is a subtle point, but it will save you significant debugging time.
In REST, errors are simple and follow familiar conventions. You receive an HTTP status code: 404 for not found, 403 for forbidden, 500 for a server error. Your client inspects the status code and decides what to do. It is clear, predictable, and widely understood by every tool in the ecosystem.
In GraphQL, things get more nuanced. If you request three fields and one of them fails, GraphQL returns a partial success — the data for the two working fields comes back alongside an errors array describing what went wrong. That is powerful when partial data is genuinely useful. But it is also easy to forget to check the errors array and accidentally display incomplete or stale data to your users.
There is also an important operational detail: GraphQL almost always returns an HTTP 200 status, even when something has failed. This breaks the HTTP semantics that monitoring tools, proxies, and alerting systems expect, and you will need to account for it in your logging and alerting setup.
gRPC uses its own structured status codes, which are more precise than HTTP codes but less universally understood outside of gRPC ecosystems.
If partial success is genuinely valuable for your use case — for example, a dashboard that can render three of four widgets when one data source is unavailable — GraphQL's model makes sense. If you want simple, atomic success-or-failure semantics, REST is the easier path.
Axis 6: Caching Strategy
Caching is one of the most underrated differences between these three technologies, and it can make or break performance at scale.
REST wins here without much contest. Because REST uses standard HTTP verbs and distinct URLs, you can place a caching layer — CloudFront, Varnish, Nginx, a CDN — in front of it with almost no configuration. The cache sees a GET to /products/42, stores the response, and serves it directly without ever touching your server. This works automatically, at the infrastructure level.
GraphQL almost always uses a single endpoint, typically /graphql, and every request is a POST. Caches cannot easily distinguish between two POST requests to the same URL because the actual query lives in the request body. Two requests that look identical to a CDN might be asking for completely different data. This means HTTP-layer caching breaks down, and you must implement response caching at the resolver level in application code. It works, but it is your responsibility, not your infrastructure's.
gRPC has no standard HTTP caching mechanism. Requests are binary and highly dynamic. If your use case involves serving the same data repeatedly to many users — a global public API, for example — gRPC is essentially a non-starter for that purpose.
Ask yourself: does my API serve the same data repeatedly to large numbers of users? If the answer is yes, REST's caching advantage is enormous, and worth prioritising over other factors.
Axis 7: API Evolution and Versioning
How do you change your API without breaking existing clients? This feels like an edge case until it becomes your most persistent headache.
In REST, the conventional approach is version numbers in the URL: /v1/users, /v2/users. This is simple and obvious, but it accumulates maintenance debt quickly. You end up running multiple versions simultaneously, either forever or until you can force all clients to upgrade — both of which are painful.
In GraphQL, you do not version the API as a whole. Instead, you deprecate individual fields. You mark a field as @deprecated with a message explaining what to use instead, and clients receive a warning at query time. New fields are added alongside old ones. Because clients ask only for what they need, they are never broken by additions — only by removals. This is a substantially smoother evolution model for APIs that need to change frequently. Deprecated fields can even remain indefinitely if the cost of removing them outweighs the benefit.
In gRPC, Protobuf's backward compatibility rules do the work. You can safely add new fields to messages without breaking existing clients, as long as you follow the rules around field numbers. You cannot change a field's type or remove a required field. This strictness prevents accidental breakage between services. When you need to make a breaking change that the rules do not allow, you create a new Protobuf definition — typically in a new file or with a new namespace like v2 in the package name. Both the old and new definitions can run in parallel. Existing clients continue using the old version. New clients or migrated clients use the new version. Once all consumers have migrated, you can retire the old version.
In short: REST gives you simple but manual versioning. GraphQL gives you graceful field-level deprecation. gRPC gives you contract safety at the cost of structural rigidity.
Axis 8: Operational Complexity
Let us talk about what happens after you deploy. How hard is this system to run day to day?
REST is the easiest to operate by a significant margin. Logs are plain text you can read in a terminal. You can reproduce any request with a single curl command. Tools like Postman, Insomnia, your browser's developer tools, and essentially every API monitoring platform understand REST natively. You have distinct endpoints, which means monitoring tools can tell you that /users is slow while /products is fast. Debugging is often a matter of copying a URL and pasting it into a browser.
GraphQL is harder. Every request hits the same endpoint. Your logs show a POST to /graphql and a large JSON body. To understand what is failing, you have to parse that body and understand the query structure. Monitoring requires more deliberate instrumentation because query shape varies widely. There is also the N+1 problem: a GraphQL query that asks for a list of users and their associated orders might trigger one database query for the user list, and then one additional query per user to fetch their orders. One client request silently becomes dozens of database calls. Solving this properly requires a batching tool like DataLoader, which adds a meaningful layer to your data access layer.
gRPC is the hardest to operate. Messages are binary and unreadable in standard log files — you need specialised tools to inspect and replay requests. Error messages can be cryptic. Most traditional API monitoring and observability tools have limited or partial gRPC support. That situation is improving, but it remains meaningfully behind REST and GraphQL in tooling maturity.
If you have a small team, limited operations experience, or a culture that values fast debugging, this axis alone may reasonably push you toward REST.
Developer Experience and the Hiring Reality
Let us look at the human side of this decision, because it matters as much as the technical side.
REST is everywhere. Every developer you hire already knows what a GET request is. The tooling ecosystem is mature, diverse, and well-documented. Debugging is accessible to people at every experience level. You can bring a junior developer onto a REST codebase and have them productive quickly.
GraphQL offers a different kind of developer experience, not necessarily better or worse, just different.
On the client side, GraphQL is a delight. Frontend developers can fetch exactly the data they need in a single request, without waiting for backend changes or working around over-fetching. They can explore the schema interactively using GraphiQL, seeing exactly what fields and relationships are available. They do not need to read separate documentation for ten different REST endpoints. The shape of the response mirrors the shape of the query they wrote, which feels natural and predictable.
On the server side, however, the experience is substantially different from REST. Instead of writing simple endpoint handlers that correspond directly to URLs, you write resolvers for every field in your schema. A deeply nested query like user { orders { products { name } } } will trigger resolvers at the user level, then at the orders level, then at the products level. This is powerful but requires thinking in terms of graphs, not resources. Many backend developers find this mental shift challenging at first.
The tooling for GraphQL server development is solid but less mature than REST's ecosystem. Debugging a GraphQL server in production requires different habits. Because every request hits the same endpoint, you cannot easily tell which queries are slow just by looking at access logs. You need to instrument your resolvers, use Apollo Studio or similar tooling, and think in terms of field-level performance rather than endpoint-level performance.
The hiring reality for GraphQL is nuanced. Many frontend developers are enthusiastic about GraphQL because it improves their daily work. Backend developers are more mixed — some love the flexibility, others find it adds unnecessary complexity. The talent pool is smaller than REST's.
gRPC has the steepest learning curve. You need to understand Protobuf syntax, the code generation workflow, and HTTP/2 specifics to be productive. Experienced gRPC developers are relatively rare. The tooling ecosystem is improving but still lags meaningfully behind the other two.
This does not mean you should never use gRPC. It means you should have a concrete technical reason. "Our internal services need sub-millisecond latency and bidirectional streaming" is a reason. "It is what large tech companies use" is not.
Real-World Scenarios
Scenario one: Public API for a weather service Third-party developers will call it, responses will be cached, and you want clear documentation.
REST is the obvious choice. It speaks the universal language of the web. Every client library supports it. HTTP-layer caching works automatically. Developers will appreciate the simplicity.
Scenario two: Backend for a mobile e-commerce app The product detail screen needs product info, reviews, inventory status, and recommendations. The checkout screen needs different fields. The search screen needs a different shape again.
GraphQL is a strong candidate. It lets the mobile team request exactly what each screen needs in one round trip, reducing bandwidth usage and improving perceived performance. Build in DataLoader for batching and implement query complexity limits before you go to production.
Scenario three: Internal microservices An order service needs to call a payment service, then an inventory service, then a shipping service. Latency matters and you want strong contracts between services.
gRPC wins here. At meaningful traffic, the performance difference is real. Protobuf contracts prevent type mismatches between services. And if you ever need streaming between services, it is already built in.
Scenario four: Simple internal admin dashboard Two users, one database, straightforward CRUD operations. REST is completely sufficient.
Anti-Patterns Worth Avoiding
Do not adopt GraphQL because it feels modern. Teams have spent weeks setting up resolvers and schema stitching for simple CRUD applications that would have been done in days with REST. The N+1 problem catches people off guard.
Do not expose gRPC directly to browsers. You will end up building and maintaining a REST-to-gRPC translation layer that becomes its own source of bugs and latency. That layer defeats the performance advantage you were chasing.
Do not use REST to fake real-time. Polling every few seconds is wasteful and slow. gRPC streaming or WebSockets already solve this cleanly. Use the right tool.
Do not assume you have to pick just one. Many successful production systems use REST for public APIs, GraphQL as a backend-for-frontend layer for mobile clients, and gRPC for internal service-to-service communication. They coexist cleanly, each doing what it does best.
Gaps Worth Knowing About
A few important topics that typically require more exploration as your system grows:
Security model. REST and GraphQL have meaningfully different attack surfaces. GraphQL's flexibility means a single malformed query can trigger enormous server load — query depth attacks and introspection abuse are real threats that require deliberate mitigation. gRPC's binary protocol makes certain attacks harder but its tooling makes auditing harder too.
Schema design. The quality of your Protobuf schema (gRPC) or GraphQL schema matters enormously for long-term maintainability. Poor schema design early creates compounding pain. For GraphQL specifically, schema stitching and federation are important topics if you expect your graph to grow across multiple teams or services.
Testing strategy. REST is trivially testable with any HTTP client. GraphQL requires testing your resolvers, your schema, and your batching layer independently. gRPC testing requires Protobuf tooling and is meaningfully harder to do casually.
Authentication and authorisation. All three approaches work with standard authentication patterns like JWT tokens or API keys. The token is typically sent in an HTTP header, which works identically for REST, GraphQL, and gRPC. Authentication — verifying who the user is — does not differ meaningfully between them.
Authorisation — deciding what the user is allowed to do — is where differences appear.
In REST, authorisation is typically applied at the endpoint level. You have an endpoint like DELETE /users/{id}. Before executing that endpoint, your code checks whether the authenticated user is allowed to delete this specific user. This is straightforward because the endpoint represents a single action on a single resource. You write one check per endpoint, and the rules are easy to reason about.
In GraphQL, authorisation can be applied at multiple levels. You might need to check whether the user is allowed to query a certain field on a certain object, or whether they are allowed to mutate a specific piece of data. Because a single GraphQL query can request many different fields across many different types, you may need to implement authorisation checks inside each resolver. This is more flexible — you can hide individual fields from unauthorised users while still returning other fields — but it is also more granular and easier to accidentally forget. Many teams implement field-level authorisation by checking permissions inside each resolver function.
In gRPC, authorisation is typically applied at the method level. Each RPC method is like an endpoint. You check permissions before executing the method. This is similar to REST in simplicity. The binary nature of gRPC does not change the authorisation story much. The main difference is that gRPC is often used in internal service-to-service communication, where authorisation may rely on service identities (like mTLS) rather than user identities carried in tokens.
The practical takeaway: if you need fine-grained, field-level authorisation — for example, showing a user's email address to admins but not to other users — GraphQL makes that pattern more natural than REST. If you need simple, endpoint-level rules, REST and gRPC give you that with less complexity.
Your Final Takeaway
The best API architecture is not the most powerful one, the fastest one, or the most talked-about one.
The best API architecture is the one whose trade-offs you understand and are prepared to live with.
REST trades flexibility for simplicity and excellent caching. GraphQL trades server-side complexity for client-side flexibility and precise data fetching. gRPC trades universal compatibility for raw speed and streaming.
The tradeoffs are the design. And which set of trade-offs you want depends entirely on your specific problem.
So do not ask "which API is best?" Ask: who is calling my API? What data do they need, and how much of it varies by client? How fast does it need to be, and where is the bottleneck? Do I need streaming? Can my team handle the operational complexity?
Answer those questions, and the right choice will reveal itself.
About N Sharma
Lead Architect at StackAndSystemN Sharma is a technologist with over 28 years of experience in software engineering, system architecture, and technology consulting. He holds a Bachelor’s degree in Engineering, a DBF, and an MBA. His work focuses on research-driven technology education—explaining software architecture, system design, and development practices through structured tutorials designed to help engineers build reliable, scalable systems.
Disclaimer
This article is for educational purposes only. Assistance from AI-powered generative tools was taken to format and improve language flow. While we strive for accuracy, this content may contain errors or omissions and should be independently verified.