Learning Paths
Last Updated: May 5, 2026 at 21:00
Microservice Communication Patterns: The 7 Types Every Architect Should Understand
A practical guide to request-response, queues, pub/sub, streaming, and more—how they work together, their trade-offs, and how to design resilient systems with confidence
Every microservice architecture is shaped by the communication choices behind it. This guide explores the seven fundamental ways services communicate—from request-response to streaming—and shows how they fit together in real production systems. Rather than just listing patterns, it highlights the strengths each approach brings and the trade-offs that come with them. By the end, you’ll have a clear mental model for choosing the right pattern with confidence and designing systems that behave predictably under pressure.
Introduction
Microservices communicate for different reasons. Sometimes a user is waiting for an answer — that demands strong consistency and an immediate response. Other times, a background job can finish minutes later. Sometimes one service needs to notify many others. Sometimes you need to replay history to rebuild state.
These different forces — consistency, timing, fan-out, durability — determine which communication patterns make sense. And every pattern comes with trade-offs. There is no free lunch. There is only a set of costs and benefits you choose to accept.
This guide does three things. First, it gives you a lens: five dimensions to evaluate any communication choice. Second, it walks through the seven fundamental patterns that emerge from those trade-offs. Third, for each pattern, you'll learn what problem it solves, how it fails in production, and what to monitor so you're not surprised at 2 AM.
The fundamental split: sync vs. async
Before we get to the five dimensions, understand this: synchronous communication is a phone call — you wait for an answer. Asynchronous is email — you send and walk away. Synchronous systems fail immediately and visibly. Asynchronous systems fail slowly and invisibly. Every pattern below is a variation of this core choice.
The lens: five dimensions
Every communication choice is a trade-off across five dimensions. We'll apply these to each of the seven patterns:
- Temporal coupling — Do both services need to be alive at the same time?
- Consistency — Do you need an answer now, or can it arrive eventually?
- Failure handling — When something breaks, what happens?
- Operational complexity — How hard is this to debug at 2 AM?
- Cost of change — How difficult is adding a new consumer or changing a schema?
These five dimensions matter because they directly predict how a system behaves when things go wrong — not if, but when.
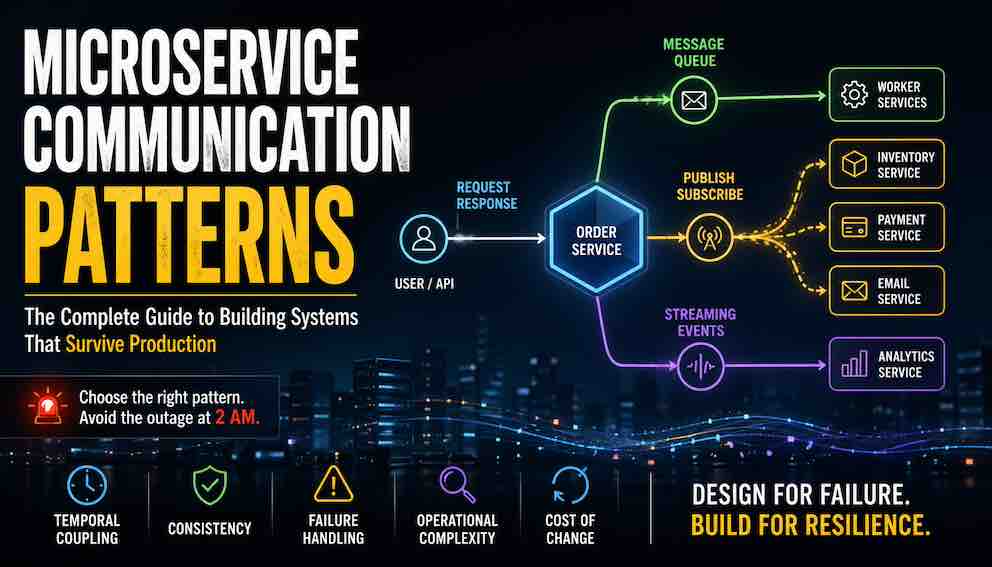
One order. Seven patterns.
Consider a real system. A user clicks "place order." The API validates the cart and returns an order ID immediately. Behind the scenes, that single action triggers a cascade: an order event travels to a queue, fans out to multiple subscribers, and lands in a stream for analytics.
One user action. Seven communication types.
Here's how they fit together in a real architecture, not as a menu of alternatives but as layers that solve different constraints:
- Type 1 (Immediate Response): The user request enters here. The system must decide quickly and return a result.
- Type 2 (Deferred Work): After the API returns the order ID to the user, the remaining work — inventory reservation, payment processing, email confirmation — moves into a message queue. This keeps the user-facing path fast and lets background workers scale independently.
- Type 3 (Event Distribution): Events fan out to multiple independent services through pub-sub.
- Type 4 (Historical Streaming): Events also land in a replayable stream for analytics and state reconstruction.
- Type 5 (Distributed Coordination): When business logic spans services, sagas coordinate multi-step consistency.
- Type 6 (Real-Time Edge): Push updates flow directly to users through WebSockets or SSE.
- Type 7 (Batch Processing): Slow, large-scale computation runs on a schedule.
All seven can coexist in the same production system.
Type 1: Immediate Response (Request-Response)
What it is
The user needs an answer immediately. "Did the order go through?" "Is this username available?" "Was the payment approved?"
In immediate response communication, Service A calls Service B and waits. B does its work and sends back an answer. A does nothing else until that answer arrives. This is REST. This is gRPC. This is how most microservices start talking to each other.
Think of it like a phone call. You dial. The other person picks up. You talk. They answer. You hang up. You were blocked the entire time.
The dimensions at a glance
Before we dive into how this breaks, here is where Type 1 sits on our five dimensions:
- Temporal coupling: High. Both services must be alive at the same time. If B is down, A fails immediately.
- Consistency: Immediate. You get an answer now, not eventually.
- Failure handling: Painful. One slow service pulls down everything that depends on it.
- Operational complexity: Low. Request-response is simple to build and debug because everything happens inside a single request context.
- Cost of change: Moderate. Changing a schema affects the caller immediately. Both sides often need to update together.
How cascading failure happens
Here is the classic failure pattern for immediate response systems.
Service A calls Service B. Service B calls Service C. This is a chain three services deep. Everything is working fine. Then Service C gets slow. Maybe its database is under pressure. Maybe it is garbage collecting. Maybe someone deployed a slow query.
Service C does not fail. It just slows down. A request that usually takes 10 milliseconds now takes 5 seconds.
Now watch what happens to Service B. Service B has a fixed number of threads — say, 50 threads available to handle incoming requests. Each thread that calls Service C now hangs around for 5 seconds instead of 10 milliseconds. Those 50 threads fill up quickly. New requests to Service B start排队ing. Soon Service B cannot respond to Service A at all.
Service A is also waiting. Its threads fill up too. Now the entire chain is collapsed. And here is the cruel detail: no single service is fully down. Service C is just slow. Service B is just busy. But the system is dead.
This is cascading failure. It is the signature wound of synchronous communication.
Why retries make it worse
When Service A times out waiting for B, it often retries. Maybe the slowness was temporary.
But here is what actually happens. Service A has 100 incoming requests. All 100 time out. All 100 retry at the exact same moment. Now A sends 200 requests to B instead of 100. B is already struggling. Now it is buried.
This is a retry amplification loop.
Circuit breakers.
A circuit breaker solves this by failing fast instead of propagating slowness. When calls to B fail too often, the breaker trips. A stops calling B entirely for a set time, letting B recover. After that time, A tries one call. If it works, traffic resumes. If not, the breaker stays open.
The critical rule: circuit breakers must exist at every hop, not just the entry point. If only A protects itself from B, but B has no breaker for C, then C can still kill B — and B will still kill A. You need protection at every level.
When to use Type 1
Use immediate response when a human is waiting for an answer. That is the only time you genuinely need this pattern.
Keep your latency budget in mind, not your hop count. A user will tolerate 200 milliseconds. They will not tolerate 2 seconds. If you have a chain of three services, each has about 65 milliseconds to do its work. That is tight but possible. If you have a chain of five services, each gets 40 milliseconds. That is very hard.
Here is a good rule of thumb: if your call chain exceeds three services deep, ask whether an asynchronous handoff belongs in the middle. Does that third service really need to answer before you return to the user? Or could it finish its work in the background?
What to monitor
If you use Type 1, monitor these things:
- Request latency at each hop. You need to know not just that A is slow, but whether B or C is the culprit.
- Thread pool utilization. If threads are near capacity, you are close to cascading failure.
- Circuit breaker state. Know when breakers are open. That is a sign of downstream distress.
- Retry rates. A spike in retries often precedes a collapse.
The failure you are guaranteed.
With Type 1, you are guaranteed this: one slow downstream service will eventually take down everything upstream of it. Not if. When. The only question is whether you have circuit breakers and timeouts configured well enough to limit the blast radius.
Type 2: Deferred Work (Message Queues)
What it is
Back to our order system. The user has their order ID. The API returned a response in 50 milliseconds. The user is happy.
But the system is not done. It needs to reserve inventory. Charge the payment. Send a confirmation email. Send data to analytics. None of this needs to happen before the user gets their answer.
This is deferred work. You put a task in a queue and walk away. A worker picks it up and processes it — maybe one second later, maybe ten seconds later. The user never waits.
How it works
One service — the producer — sends a message to a queue. One or more services — consumers — pull messages from that queue and process them.
The queue sits between producer and consumer. It decouples them completely. The producer does not know who consumes. The consumer does not know who produced. The queue just holds messages until someone takes them.
The dimensions at a glance
- Temporal coupling: Zero. The producer and consumer do not need to be alive at the same time. The queue holds the message.
- Consistency: Eventual. The work happens when it happens, not immediately.
- Failure handling: Graceful. If a consumer crashes, the message stays in the queue (or returns to it). Another consumer picks it up.
- Operational complexity: Moderate. You need to monitor queue depth. That is the main new thing you did not have to think about before.
- Cost of change: Low. Adding a new producer or consumer rarely breaks existing ones, as long as the message format stays compatible.
Competing consumers
You do not have to run one consumer. You can run many instances of the same consumer, all reading from the same queue.
This is called competing consumers. Each message goes to exactly one consumer. If you have ten consumers and one hundred messages, each consumer gets about ten messages.
This gives you horizontal scaling. The queue is getting deeper? Add more consumers. Throughput goes up. No code change required.
Idempotency is not optional
Here is the complication. Networks fail. Consumers crash after processing a message but before acknowledging it to the queue. When the consumer restarts, the queue delivers the same message again.
This means you must design every consumer to be idempotent. Processing the same message twice must produce the same result as processing it once. If you reserve inventory twice for the same order, you have a problem. If you send the same confirmation email twice, the user gets confused. Idempotency is not a best practice. It is a requirement.
Backpressure: the signal you get for free
In synchronous systems, the only signal of overload is latency and errors. By the time you see that signal, you are already in an incident.
In asynchronous systems, you get a different signal: queue depth. A growing queue means consumers are falling behind. This signal appears before latency spikes. Before errors. Before the pager goes off.
This is one of the most underappreciated advantages of async design. The queue tells you there is a problem while you still have time to respond.
Failure modes
Poison message.
A malformed event crashes the consumer every time it tries to process it. The consumer restarts. It pulls the same message. It crashes again. Restart. Crash. Restart. Crash.
The signature: consumer restarts climb while the processed message count stays flat.
The fix: after three retries, route the message to a dead letter queue. Alert on dead letter queue messages. Investigate why that message cannot be processed.
Silent backlog.
A consumer hangs. No errors. No crashes. It just stops processing. The queue depth climbs. No one notices because nothing is obviously broken.
The fix: treat queue lag as a first-class health metric. Graph it. Alert on it. Do not treat it as an afterthought.
When to use Type 2
Use deferred work for anything that happens outside the user request. Image resizing. Email delivery. Payment processing. Downstream notifications. Data syncs.
The rule is simple: if the user is not waiting for the result, it belongs in a queue.
What to monitor
- Queue depth (how many messages are waiting)
- Consumer lag (how old the oldest unprocessed message is)
- Dead letter queue size
- Consumer processing time per message
The failure you are guaranteed
With Type 2, you are guaranteed this: work will eventually stop without any errors surfacing. A silent backlog will grow. The queue will fill. The pager will stay silent until someone notices that emails stopped sending two hours ago. Monitor queue depth or discover failures the hard way.
Type 3: Event Distribution (Publish-Subscribe)
What it is
The order event needs to reach multiple services. Inventory needs to reserve stock. Email needs to send a confirmation. Analytics needs to record the event.
In deferred work (Type 2), one message goes to one consumer. That does not work here. You would need to send the same message three times or create a coordinating service that knows about all three. Both are bad.
With publish-subscribe, one publisher emits an event. Every subscriber that wants that event receives a copy. None of the subscribers know about each other. Inventory does not know email exists. Email does not know analytics exists.
The dimensions at a glance
- Temporal coupling: Zero. Publisher and subscribers do not need to be alive at the same time.
- Consistency: Eventual, and speeds vary per subscriber. Inventory may process in 10 milliseconds. Analytics may take 10 seconds. Both are fine.
- Failure handling: Independent. If email crashes, inventory and analytics keep working.
- Operational complexity: Moderate to high. You now have multiple consumers to track, plus the pub-sub system itself.
- Cost of change: Low to add a consumer. High to change a schema — a bad change can break every subscriber.
Queue vs. Pub/Sub vs. Stream
These three are often confused. Here is the distinction:
- Queue: One message goes to one consumer. Use this to distribute work.
- Pub/Sub: One message goes to all subscribers. Use this to broadcast facts.
- Stream: An ordered, replayable log. Use this as a system of record.
In our order system, you might use all three: a queue for deferred work (reserve inventory), pub/sub for broadcasting the order event (notify email and analytics), and a stream for audit history (replay later).
When to use Type 3
Use publish-subscribe when multiple services need to react to the same event without being coupled to each other.
One rule: emit facts, not instructions. Publish "order placed," not "send email." Facts let each subscriber decide what to do. Instructions couple the publisher to downstream behavior. When you publish "send email," you cannot later add an SMS subscriber without changing the publisher. When you publish "order placed," you can add SMS later and no one changes.
What to monitor
- Subscriber lag — how far behind each consumer is
- Dead letter queues per subscriber
- Events published vs. events delivered per subscriber
The failure you are guaranteed
With Type 3, you are guaranteed this: one day, a subscriber will silently stop processing because someone changed an event schema. No errors. No alerts. Just missing data. Without a schema registry, you will discover this when someone asks why reports are wrong.
Type 4: Historical Streaming (Event Logs)
What it is
Analytics does not need real-time accuracy. A five-second delay is fine. But analytics has a harder problem: when someone changes a query or adds a new report, they need to reprocess history. They need to go back to last Tuesday at 3 PM and run the new logic on old events.
Queues cannot do this. Messages disappear after consumption. Pub-sub cannot do this. Consumers move on. Streams are different. Streams accumulate. They keep every event in order, forever, as a replayable history. The stream becomes the system of record.
How offset management works
Every message in a stream has a sequential ID. Consumer tracks its position — the offset. Crash at offset 100? Resume at 100. Need to reprocess from last Tuesday? Go back to offset 87,000 and start over.
This is the superpower of streams. You are not just processing events. You are keeping a time machine.
Dimensions at a glance
- Temporal coupling: Zero, but consumers must keep up with the stream rate.
- Consistency: Eventual, with full replayability.
- Failure handling: Durable. The stream never loses data.
- Operational complexity: High. Offsets, consumer groups, and rebalancing require careful management.
- Cost of change: Moderate. Adding a new consumer is easy. Changing the schema affects all future replays.
Failure mode: offset mismanagement
Here is the trap. Process a message but crash before committing the offset? You process it again on restart. Commit the offset before processing completes, then crash? You lose the message entirely.
There is no perfect answer. The only solution is idempotency. Your consumer must handle duplicate processing and tolerate at-least-once or at-most-once delivery. Idempotency is not optional for streams. It is a correctness requirement.
The dual-write problem.
You update your database. Then you try to publish an event to the stream. What if the database commit succeeds but the event publish fails? Your database shows the change, but downstream systems never learn about it. You are inconsistent.
Following patterns solve this:
- Transactional outbox: Write the event to an outbox table inside the same database transaction as your data change. A separate poller reads the outbox and publishes. Creates at-least-once delivery. Every consumer must be idempotent. This is the right starting point for most teams.
- Event sourcing: The event log becomes the primary source of truth. State is derived by replaying events. This eliminates the dual-write problem entirely. But it requires rethinking your data model from the ground up.
When to use Type 4
Use streams when the event log itself has value. Audit trails. Analytics. State reconstruction. Temporal debugging. If you ever ask "what happened last Tuesday at 3 PM," you want a stream.
The failure you are guaranteed
With Type 4, you are guaranteed this: offsets will be mismanaged. You will lose a message or process it twice. Idempotency is not a best practice. It is your only defense.
Type 5: Distributed Coordination (Sagas)
What it is
Payment charges — success. Inventory reserves — failure, out of stock. The payment already went through. In a database, you would roll back the transaction. But you cannot roll back across service boundaries. Payment service does not know about Inventory service. There is no global transaction.
The saga pattern solves this. It breaks a distributed transaction into a sequence of local transactions, each triggering the next. If any step fails, compensating transactions execute in reverse — reverse the payment, release the inventory.
How it works: two approaches
Choreography. No central coordinator. Services listen for events and react. Payment emits "payment_charged." Inventory hears it and tries to reserve. If inventory fails, it emits "inventory_reserve_failed." Payment hears that and issues a refund.
Choreography is decoupled. Easy to start with. But when you have eight steps, the flow becomes invisible. You cannot look at one place and understand the whole saga.
Orchestration. A central coordinator issues commands and tracks state. The coordinator tells Payment: "charge $50." Payment replies "done." Coordinator tells Inventory: "reserve item." Inventory replies "failed." Coordinator tells Payment: "refund $50."
Orchestration puts the flow in one place. Visible. Debuggable. But the coordinator becomes a coupling point and a potential bottleneck.
Which to choose
Use choreography for simple, independent flows with three steps or fewer. Use orchestration when you need visibility into multi-step processes or when compensating logic is complex.
When to use Type 5
Use sagas for any business operation that spans multiple service boundaries where partial failure requires explicit rollback. Order fulfillment. Booking travel. Transferring money.
Without a deliberate saga design, you have an implicit one — random compensating logic scattered across services. That produces inconsistencies that require manual intervention to fix.
What to monitor
- Saga step failures and compensations triggered
- Long-running sagas that never complete
- Compensations that fail (those need manual handling)
The failure you are guaranteed
With Type 5, you are guaranteed this: a compensating transaction will eventually fail. The payment refund will fail. The inventory release will fail. You will need a dead letter queue for failed compensations and an alert for manual intervention. Plan for it.
Type 6: Real-Time Edge (WebSockets, SSE)
What it is
Not everything ends at an API response. Modern systems push data to clients as it happens — live scores, stock prices, chat messages, notifications.
Two main technologies handle real time communication.
WebSockets. Bidirectional, persistent connection. The server can push to the client. The client can push to the server. Right for chat, live collaboration, and gaming.
Server-Sent Events (SSE). One-way, server-to-client streaming. The client opens a connection. The server pushes updates. The client cannot send data back over the same connection. Right for live feeds, notifications, and dashboards.
The dimensions at a glance
- Temporal coupling: High. The connection must stay alive. If it drops, updates stop.
- Consistency: Near-immediate. Updates push as they happen.
- Failure handling: Complex. You need reconnection logic, backoff strategies, and state sync.
- Operational complexity: Moderate to high. Persistent connections consume server resources. Connection counts matter differently than request counts.
Failure mode: silent disconnect
The UI looks alive. The connection count looks stable. But updates have stopped flowing. No error. No reconnection. Just silence.
The signature: connection count stays flat while message rate drops to zero.
The fix has two parts. First, application-level heartbeats — the client sends a ping every 30 seconds, the server responds. Miss two heartbeats? Assume dead and reconnect. Second, exponential backoff with jitter on reconnect — do not let all clients retry at the same moment, or you create a thundering herd that takes down your server.
When to use Type 6
Use real-time edge for any client that needs live updates without polling. The trade-off is connection overhead and server-side state versus polling latency (updates delayed by the poll interval) and wasted requests (most polls return nothing).
What to monitor
- Active connection count
- Message rate per connection
- Heartbeat failures
- Reconnection storms
The failure you are guaranteed
With Type 6, you are guaranteed this: clients will silently disconnect while the UI appears live. Users will stare at stale data. No one will alert you. Without heartbeats, you will discover this from a support ticket.
Type 7: Batch and Scheduled (Cron, Pipelines)
What it is
Not everything is event-driven. Not everything is request-driven. Some of the most important systems run on time, not triggers.
Cron jobs. Periodic tasks. Reconciliation between systems. Report generation. Data syncs. Run every hour, every night, every Monday.
Batch pipelines. Large-scale data transformation. ETL jobs. Aggregated analytics. Process millions of records in one run.
The dimensions at a glance
- Temporal coupling: Zero. The job runs on its own schedule.
- Consistency: Eventual, on the schedule's terms.
- Failure handling: Simple. Retry on the next run. Or investigate and backfill.
- Operational complexity: Low. But monitoring job success and failure is still essential.
Failure mode: delayed correctness
A batch job fails silently. Or worse — it runs but produces wrong results. No errors. No alerts. Just bad data.
Days later, someone notices inventory counts do not match. Or a report is missing. Drift has been accumulating quietly.
The signature is not errors. It is the absence of expected changes. Metrics flatline. Row counts stop matching. Reports do not arrive. By the time you notice, the damage is hours or days old. Manual correction is the only fix.
When to use Type 7
Use batch processing for any work that operates on the assumption "by the time this runs, all relevant data should exist." End-of-day reconciliation. Nightly aggregates. Weekly reports.
Batch is boring in the best possible way. It is predictable. It is understood. And it is often the most critical system in your stack — the one that keeps the numbers right.
What to monitor
- Job success/failure (obvious, but often overlooked)
- Row counts before and after — do they match what you expect?
- Job duration — is it getting slower?
- Output freshness — when was the last successful run and output?
The failure you are guaranteed
With Type 7, you are guaranteed this: a critical batch job will fail silently, and no one will notice until someone looks at a report that should have arrived. Monitor expected outputs, not just job exit codes.
Debugging What You Cannot See
Synchronous systems are traceable — everything happens within a single request context. Asynchronous systems are harder. Producer and consumer live in different timelines, on different machines, separated by queues and partitions.
Correlation IDs. Generate a unique ID at the system's entry point. Pass it to every downstream service — in HTTP headers, message headers, wherever metadata travels. Every service logs with it and passes it forward. When something goes wrong, search logs for a single ID and reconstruct the entire journey across every service boundary.
Separate your latency signals. In async systems, a two-second delay could mean a slow consumer or a backed-up queue. Those require different fixes — scaling consumers versus scaling infrastructure — and collapsing them into a single latency metric hides the distinction. Trace queue wait time separately from consumer processing time.
The Closing Insight
Every communication type you choose comes with a trade-off. The question is not which one is "best." The question is which trade-offs fit your system's real constraints.
- Type 1 (Immediate Response) gives you simplicity and immediate answers. The cost is cascading failure. Accept it and add circuit breakers at every hop.
- Type 2 (Deferred Work) gives you decoupling and backpressure signals. The cost is silent backlogs. Accept it and monitor queue depth.
- Type 3 (Event Distribution) gives you broadcast without coupling. The cost is schema evolution pain. Accept it and add a schema registry early.
- Type 4 (Historical Streaming) gives you replayability and audit trails. The cost is offset management. Accept it and design idempotent consumers.
- Type 5 (Distributed Coordination) gives you cross-service consistency. The cost is compensating failures. Accept it and plan for manual intervention.
- Type 6 (Real-Time Edge) gives you live updates without polling. The cost is silent disconnects. Accept it and add heartbeats.
- Type 7 (Batch Processing) gives you scheduled, predictable execution. The cost is delayed correctness failures. Accept it and monitor outputs, not just job status.
There is no perfect communication pattern. There is only the pattern whose costs you are willing to pay and whose failure modes you know how to detect.
About N Sharma
Lead Architect at StackAndSystemN Sharma is a technologist with over 28 years of experience in software engineering, system architecture, and technology consulting. He holds a Bachelor’s degree in Engineering, a DBF, and an MBA. His work focuses on research-driven technology education—explaining software architecture, system design, and development practices through structured tutorials designed to help engineers build reliable, scalable systems.
Disclaimer
This article is for educational purposes only. Assistance from AI-powered generative tools was taken to format and improve language flow. While we strive for accuracy, this content may contain errors or omissions and should be independently verified.